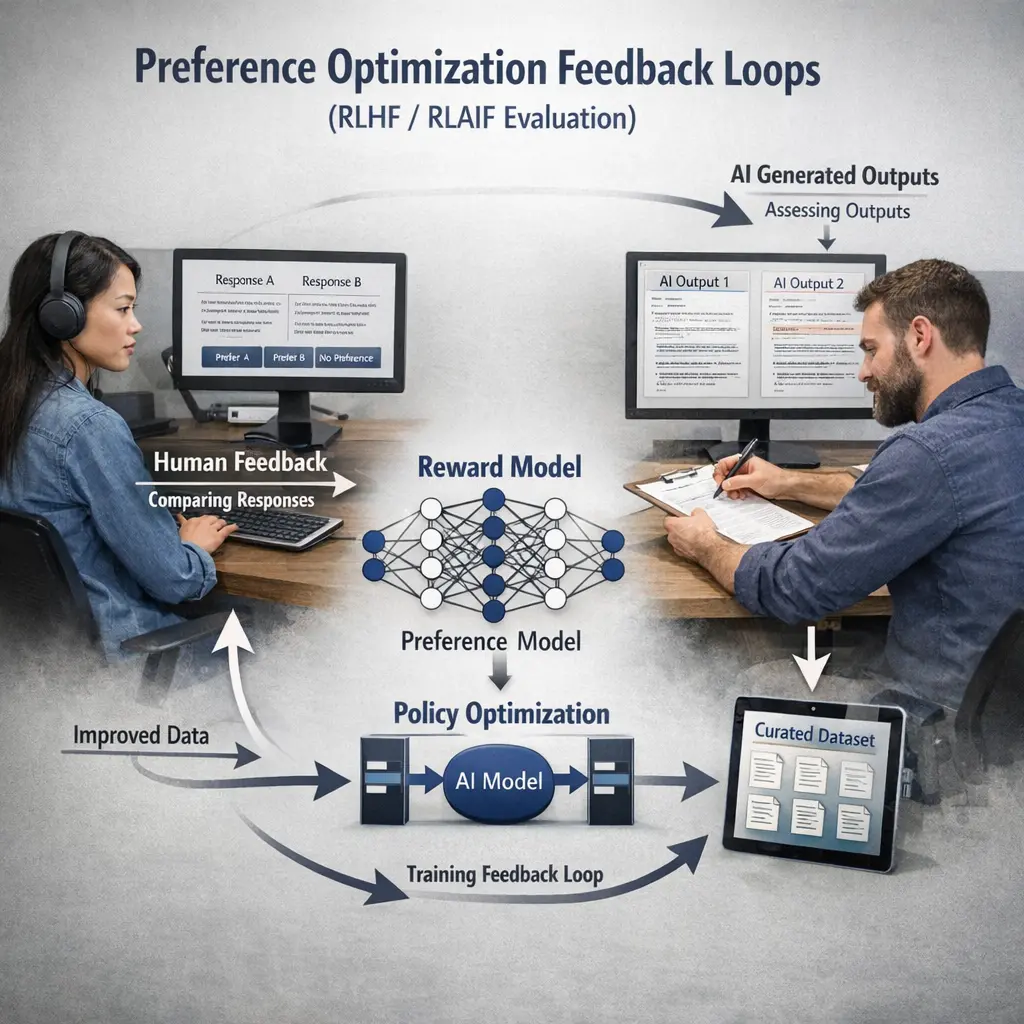
"Human Evaluation: Annotation Guidelines & Benchmarks (LLM Evaluations (evals))" refers to systematic methods for assessing large language models (LLMs) by involving human annotators. Annotation guidelines provide clear instructions to ensure consistent and objective evaluations, while benchmarks are standardized tasks or datasets used to measure model performance. Together, these processes help validate LLM outputs, identify strengths and weaknesses, and guide model improvements by comparing results across different systems and iterations.
Human Evaluation: Annotation Guidelines & Benchmarks+50
"Human Evaluation: Annotation Guidelines & Benchmarks (LLM Evaluations (evals))" refers to systematic methods for assessing large language models (LLMs) by involving human annotators. Annotation guidelines provide clear instructions to ensure consistent and objective evaluations, while benchmarks are standardized tasks or datasets used to measure model performance. Together, these processes help validate LLM outputs, identify strengths and weaknesses, and guide model improvements by comparing results across different systems and iterations.
💡 Key Takeaways
- Understand why human evaluation is essential for annotation quality and model training
- Learn how clear annotation guidelines improve consistency across annotators
- Explore how benchmarks are built to assess annotation accuracy and model performance
- Get familiar with common agreement metrics (e.g., inter-annotator agreement) and their interpretation
- Discover strategies for resolving disagreements and improving guidelines over time
❓ Frequently Asked Questions
What is human evaluation in annotation guidelines & benchmarks?
Human evaluation involves people labeling data according to predefined rules to assess quality and reliability. It helps create gold standards and validate how well automated methods perform.
What are annotation guidelines?
Annotation guidelines are the rules that tell annotators how to label data, including label definitions, decision criteria, edge cases, and examples to ensure consistent labeling.
What are benchmarks in this context?
Benchmarks are standardized datasets and evaluation protocols used to measure and compare system performance, providing gold labels, metrics, and procedures for fair comparisons.
How is annotation quality assessed?
Quality is measured using inter-annotator agreement metrics (e.g., Cohen's kappa, Fleiss' kappa, Krippendorff's alpha), along with pilot testing and ongoing quality checks.