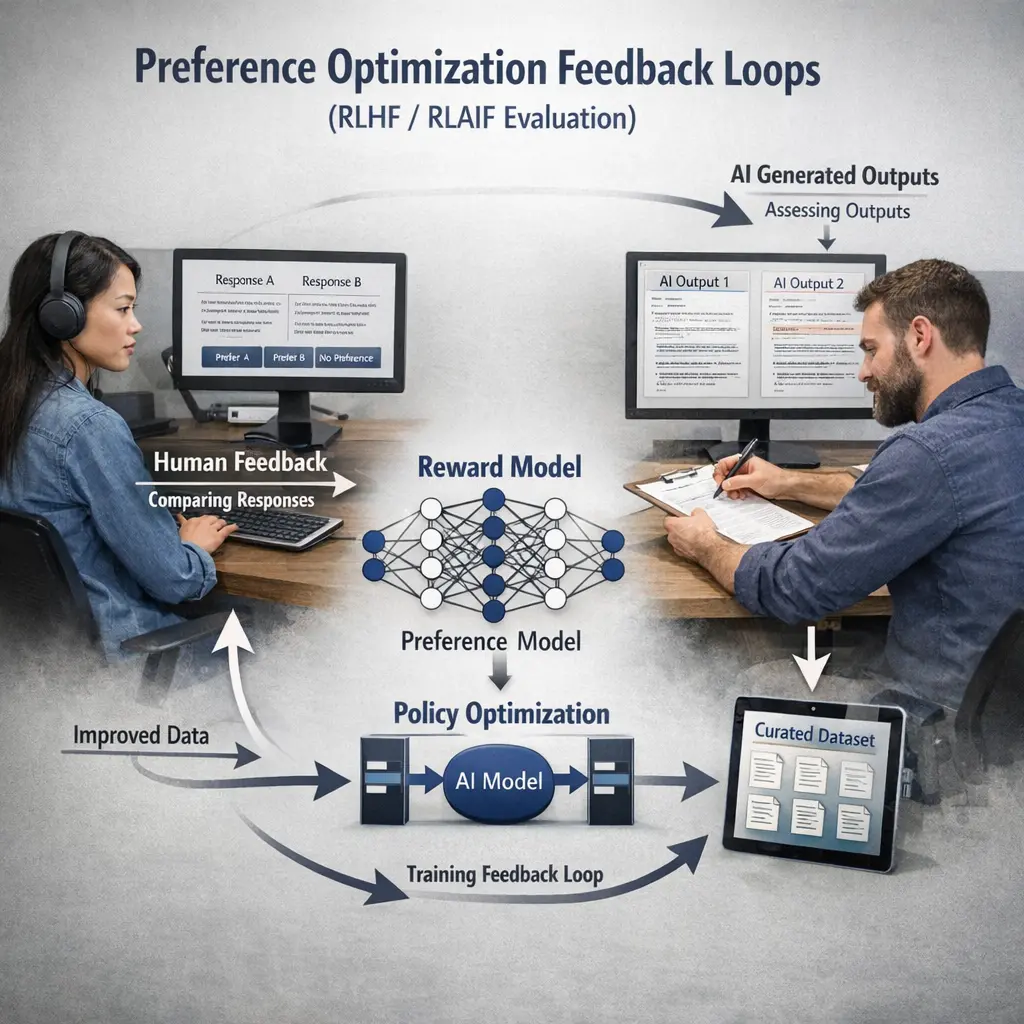
Preference Optimization Feedback Loops, such as RLHF (Reinforcement Learning from Human Feedback) and RLAIF (Reinforcement Learning from AI Feedback), are methods to align large language models (LLMs) with desired behaviors by incorporating human or AI preferences into training. Evaluation of these loops, often called LLM Evaluations (evals), involves systematically assessing how effectively these optimization processes improve model responses according to set criteria, ensuring models meet quality and safety standards.
Preference Optimization Feedback Loops (RLHF/RLAIF) Evaluation
Preference Optimization Feedback Loops, such as RLHF (Reinforcement Learning from Human Feedback) and RLAIF (Reinforcement Learning from AI Feedback), are methods to align large language models (LLMs) with desired behaviors by incorporating human or AI preferences into training. Evaluation of these loops, often called LLM Evaluations (evals), involves systematically assessing how effectively these optimization processes improve model responses according to set criteria, ensuring models meet quality and safety standards.
💡 Key Takeaways
- Learn how RLHF and RLAIF use preference signals to shape model behavior and what evaluation should confirm.
- Know common metrics and evaluation protocols for preference-based tuning, such as pairwise preference accuracy and ranking quality.
- Consider data quality, annotation consistency, diversity, and bias when evaluating preferences.
- Identify common pitfalls (reward hacking, overfitting to feedback signals) and best practices for robust offline and online evaluation.
❓ Frequently Asked Questions
What do RLHF and RLAIF stand for?
RLHF = Reinforcement Learning from Human Feedback; it uses human judgments to shape rewards and learning. RLAIF = Reinforcement Learning from AI Feedback; it uses AI-generated feedback to guide learning, often to scale feedback when humans are scarce.
What is a preference optimization feedback loop?
A cycle where outputs are scored or ranked by a feedback signal, a reward model learns from those signals, and the policy is updated to produce outputs more aligned with the preferred responses.
How is evaluation typically performed in RLHF/RLAIF?
Using held-out prompts, comparing model outputs to preferred references, validating reward models against human/AI preferences, and tracking metrics like correlation with preferences, task performance, and safety indicators.
What are common challenges to watch for?
Bias or noise in preferences, misalignment between rewards and real goals, overfitting to feedback sources, high annotation costs (for humans), and ensuring AI feedback remains reliable and safe.



