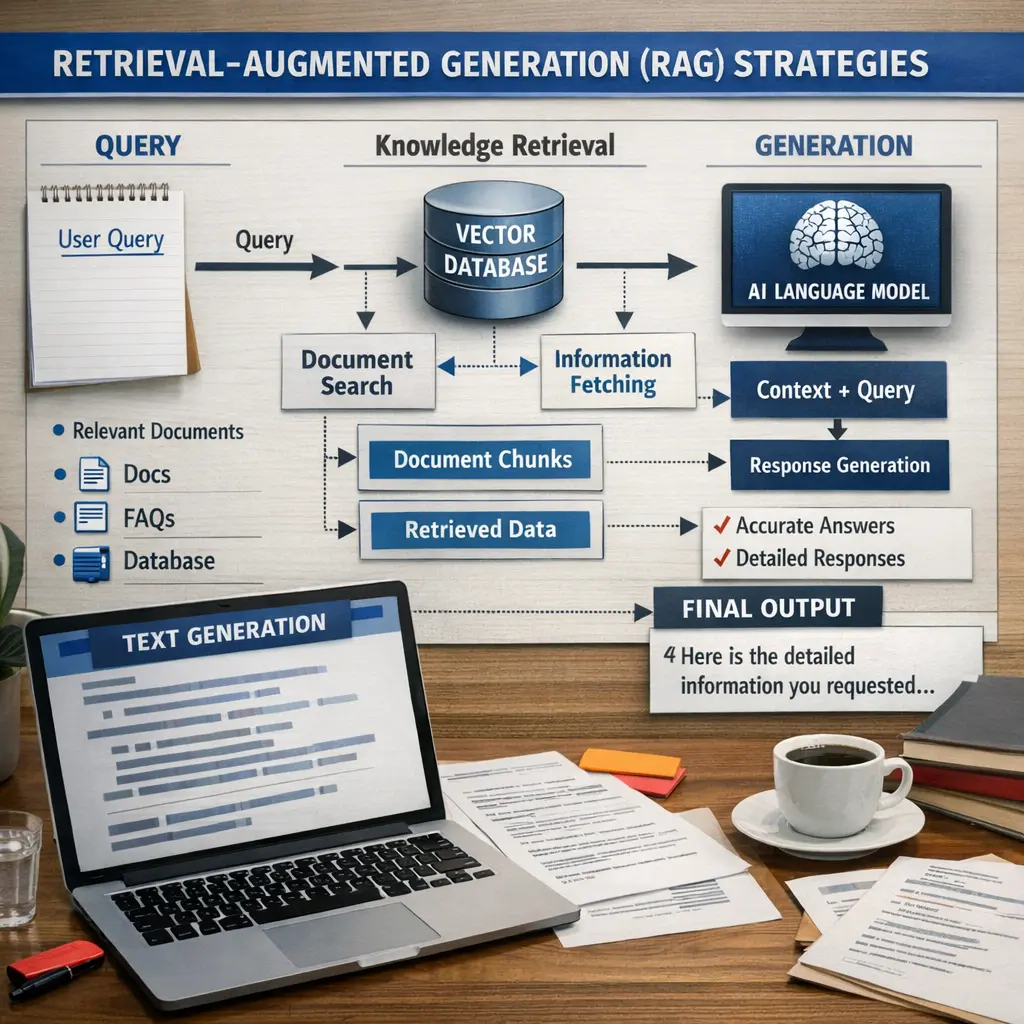
Retrieval-Augmented Generation (RAG) strategies in agent architecture combine generative AI models with information retrieval systems. In this approach, the agent first retrieves relevant data or documents from external sources, then uses a language model to generate responses based on both the retrieved information and its internal knowledge. This enhances the accuracy, relevance, and factual grounding of the generated outputs, making the agent more effective in complex or knowledge-intensive tasks.
Retrieval-Augmented Generation (RAG) Strategies
Retrieval-Augmented Generation (RAG) strategies in agent architecture combine generative AI models with information retrieval systems. In this approach, the agent first retrieves relevant data or documents from external sources, then uses a language model to generate responses based on both the retrieved information and its internal knowledge. This enhances the accuracy, relevance, and factual grounding of the generated outputs, making the agent more effective in complex or knowledge-intensive tasks.
💡 Key Takeaways
- Define Retrieval-Augmented Generation (RAG) and its core components (retriever, generator, and external knowledge sources).
- Explain how RAG uses retrieved documents to ground and improve the factual accuracy of generated responses.
- Identify common RAG strategies, including dense vs sparse retrievers and how retrieved passages are incorporated as context.
- Assess typical evaluation criteria and challenges for RAG systems, such as latency, retrieval quality, and knowledge freshness.
❓ Frequently Asked Questions
What is Retrieval-Augmented Generation (RAG)?
RAG combines a document retriever with a generator: it fetches relevant passages from an external knowledge source and then uses them to help generate an answer.
What are the main components of a RAG system?
A retriever to fetch relevant passages, a knowledge source (document store), and a generator to produce text conditioned on the retrieved passages.
What is the difference between RAG-Token and RAG-Sequence?
RAG-Sequence uses retrieved documents when generating the entire answer, while RAG-Token uses retrieved docs for each token, allowing per-token weighting of sources.
What is Fusion-in-Decoder (FiD) and how does it relate to RAG?
FiD is a retrieval-augmented approach that feeds retrieved passages into the decoder to fuse external evidence during generation, similar in goal to RAG but implemented differently.