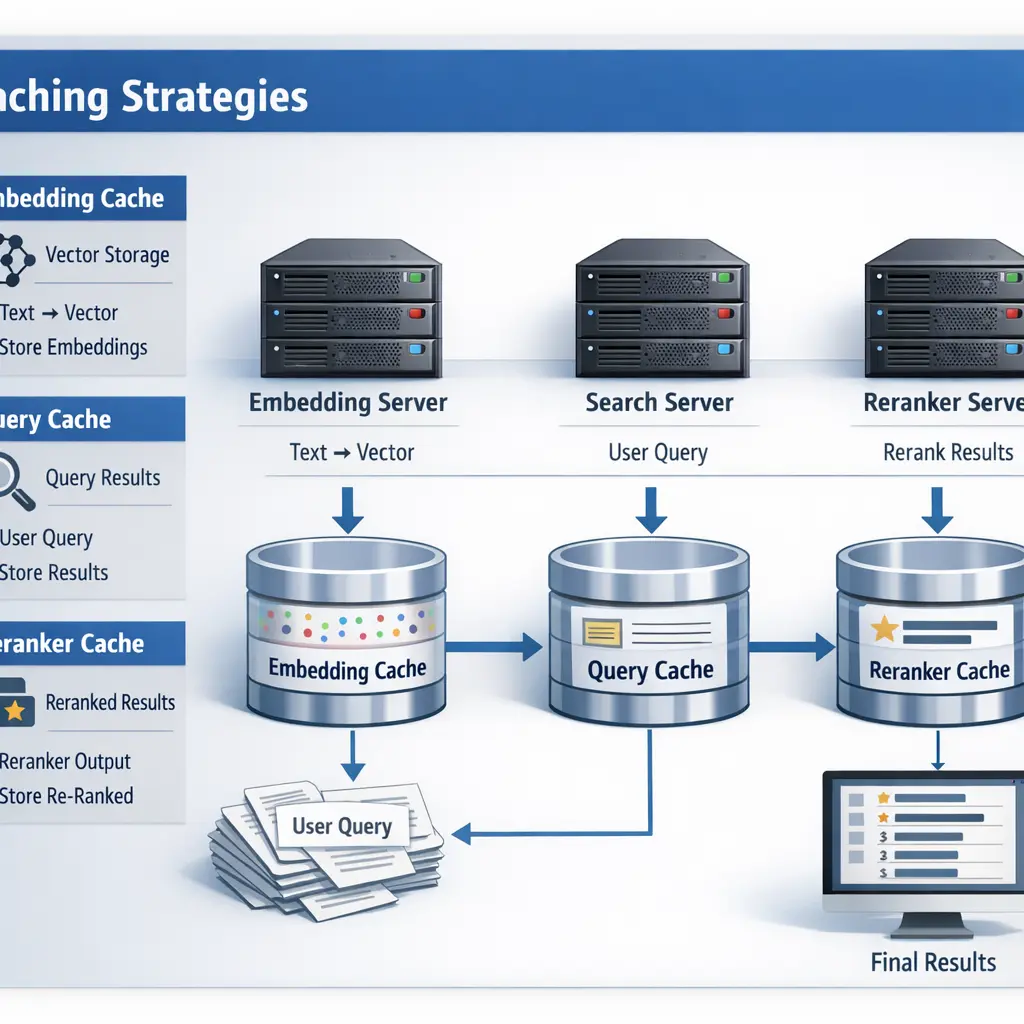
Caching strategies in Retrieval-Augmented Generation (RAG) involve storing intermediate results to improve efficiency and reduce latency. Embedding caches save vector representations of queries or documents, avoiding repeated computations. Query caches store the results of previous searches, allowing quick retrieval for identical or similar queries. Reranker caches preserve the outcomes of reranking processes, preventing redundant reranking of the same candidates. Together, these caches optimize system performance and resource usage in RAG workflows.
Caching Strategies: Embedding, Query, and Reranker Caches
Caching strategies in Retrieval-Augmented Generation (RAG) involve storing intermediate results to improve efficiency and reduce latency. Embedding caches save vector representations of queries or documents, avoiding repeated computations. Query caches store the results of previous searches, allowing quick retrieval for identical or similar queries. Reranker caches preserve the outcomes of reranking processes, preventing redundant reranking of the same candidates. Together, these caches optimize system performance and resource usage in RAG workflows.
💡 Key Takeaways
- Understand how embedding caches speed up similarity search by reusing computed embeddings and similarity results.
- Learn how query caches store and reuse frequent requests to reduce latency and backend load.
- Explore reranker caches to quickly reuse previously ordered results for popular queries.
- Discover cache invalidation and freshness strategies, including TTLs and versioning, for embeddings, queries, and rerankers.
- Compare the trade-offs and interactions between embedding, query, and reranker caches to optimize end-to-end performance.
❓ Frequently Asked Questions
What is an embedding cache and why is it used?
An embedding cache stores precomputed vector representations (embeddings) of items to speed up similarity searches and avoid re-embedding on every query.
What is a query cache in a retrieval system?
A query cache stores results or precomputed embeddings for frequently asked queries to reduce latency and repetitive computation.
What is a reranker cache and when should it be used?
A reranker cache saves results from a costly reranking step for similar candidate lists, so repeated requests can reuse prior rankings instead of recomputing.
What are common pitfalls when using these caches?
Watch for cache invalidation and staleness, memory usage, and data freshness to ensure cached results remain accurate.



