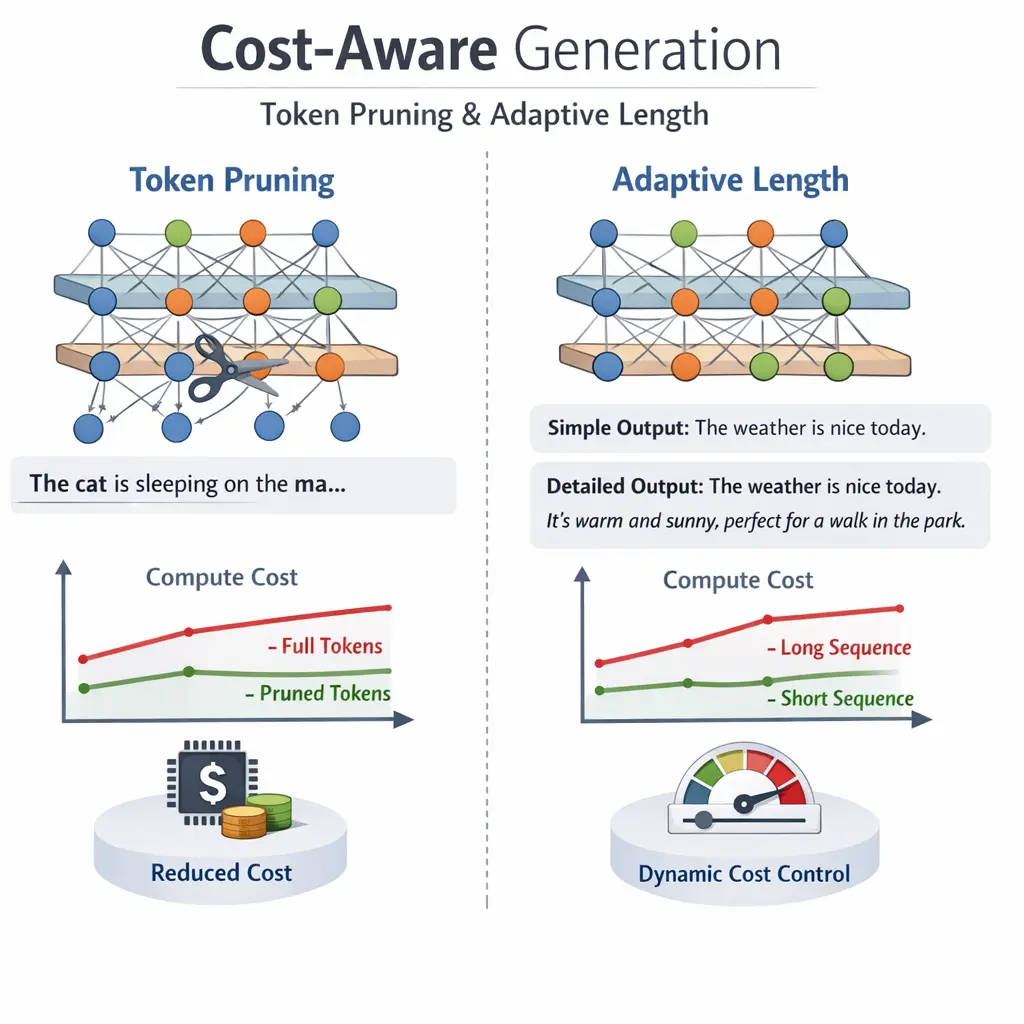
Cost-Aware Generation: Token Pruning and Adaptive Length in Retrieval-Augmented Generation (RAG) refers to optimizing text generation by selectively removing unnecessary tokens (token pruning) and dynamically adjusting the output length (adaptive length). This approach reduces computational costs and resource usage during inference, ensuring efficiency without sacrificing output quality. In RAG systems, these techniques help balance retrieval accuracy and generation expense, enabling scalable and cost-effective deployment of large language models in real-world applications.
Cost-Aware Generation: Token Pruning and Adaptive Length
Cost-Aware Generation: Token Pruning and Adaptive Length in Retrieval-Augmented Generation (RAG) refers to optimizing text generation by selectively removing unnecessary tokens (token pruning) and dynamically adjusting the output length (adaptive length). This approach reduces computational costs and resource usage during inference, ensuring efficiency without sacrificing output quality. In RAG systems, these techniques help balance retrieval accuracy and generation expense, enabling scalable and cost-effective deployment of large language models in real-world applications.
💡 Key Takeaways
- Understand cost-aware generation and how token usage affects model cost and latency.
- Learn how token pruning trims input/output tokens to save resources without sacrificing quality.
- Explore adaptive length strategies to generate outputs that fit budget or latency constraints.
- Assess trade-offs between accuracy, speed, and cost when using token pruning and adaptive length techniques.
❓ Frequently Asked Questions
What is cost-aware generation in NLP?
Cost-aware generation aims to produce text while minimizing computational or monetary costs, such as token usage or runtime, without sacrificing essential quality.
What is token pruning?
Token pruning is a technique that reduces the decoding search space by discarding low-importance or unlikely tokens, lowering compute and memory use while trying to preserve meaning.
What is adaptive length?
Adaptive length is a decoding approach that dynamically determines how many tokens to generate based on constraints or confidence, instead of sticking to a fixed output length.
How do token pruning and adaptive length affect quality?
They reduce cost but can risk losing detail or coherence if applied too aggressively. Use proper thresholds, validation, and fallback strategies to maintain acceptable quality.