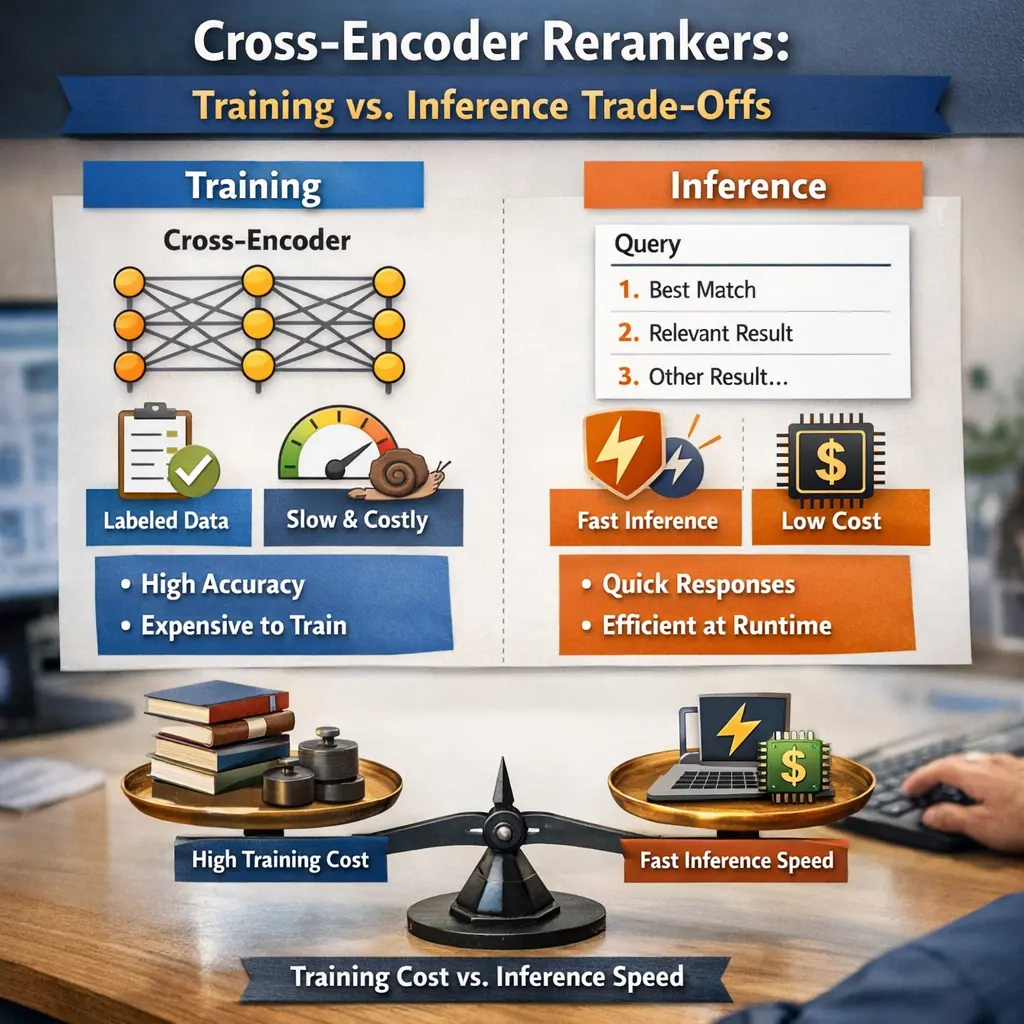
Cross-Encoder Rerankers are models used in Retrieval-Augmented Generation (RAG) to improve the quality of retrieved documents by jointly encoding query and candidate passages for relevance scoring. During training, they achieve high accuracy but are computationally expensive since each query-passage pair is processed together. In inference, this leads to slower performance compared to bi-encoders, creating a trade-off between retrieval effectiveness and efficiency. The choice depends on application requirements for speed versus accuracy.
Cross-Encoder Rerankers: Training and Inference Trade-offs
Cross-Encoder Rerankers are models used in Retrieval-Augmented Generation (RAG) to improve the quality of retrieved documents by jointly encoding query and candidate passages for relevance scoring. During training, they achieve high accuracy but are computationally expensive since each query-passage pair is processed together. In inference, this leads to slower performance compared to bi-encoders, creating a trade-off between retrieval effectiveness and efficiency. The choice depends on application requirements for speed versus accuracy.
💡 Key Takeaways
- Understand what a cross-encoder reranker is and how it scores query-document pairs in a single forward pass to boost ranking quality.
- Learn how training choices—negative sampling, data quality, and loss functions—shape a cross-encoder's effectiveness.
- Recognize the inference trade-offs: cross-encoders are accurate but computationally expensive, so they are usually applied to a small candidate set.
- Explore common deployment patterns, typically a two-stage pipeline with a fast retriever followed by a cross-encoder reranker.
- Discover cost-saving techniques to balance speed and accuracy, such as knowledge distillation, quantization, mixed precision, and hybrid retrieval strategies.
❓ Frequently Asked Questions
What is a cross-encoder reranker?
A model that jointly encodes a query and a candidate document to produce a relevance score, using cross-attention between them. It’s usually more accurate but slower at inference, making it ideal for re-ranking after an initial retrieval step.
What is the training vs inference trade-off for cross-encoder rerankers?
Training aims to learn accurate relevance scoring, while inference must evaluate many candidates quickly. The trade-off is higher accuracy versus higher latency and compute; common solutions include distillation and staged retrieval.
How does a cross-encoder differ from a bi-encoder in reranking?
A cross-encoder processes the query and document together, capturing detailed interactions and usually achieving better ranking but slower inference. A bi-encoder encodes them separately, enabling fast, scalable retrieval but often with lower accuracy.
What strategies help reduce inference time for cross-encoder rerankers?
Use a two-stage pipeline (bi-encoder to filter candidates, cross-encoder to top-k re-rank), model distillation to smaller models, quantization or mixed-precision, shorter input sequences, and caching or early-exit mechanisms.



