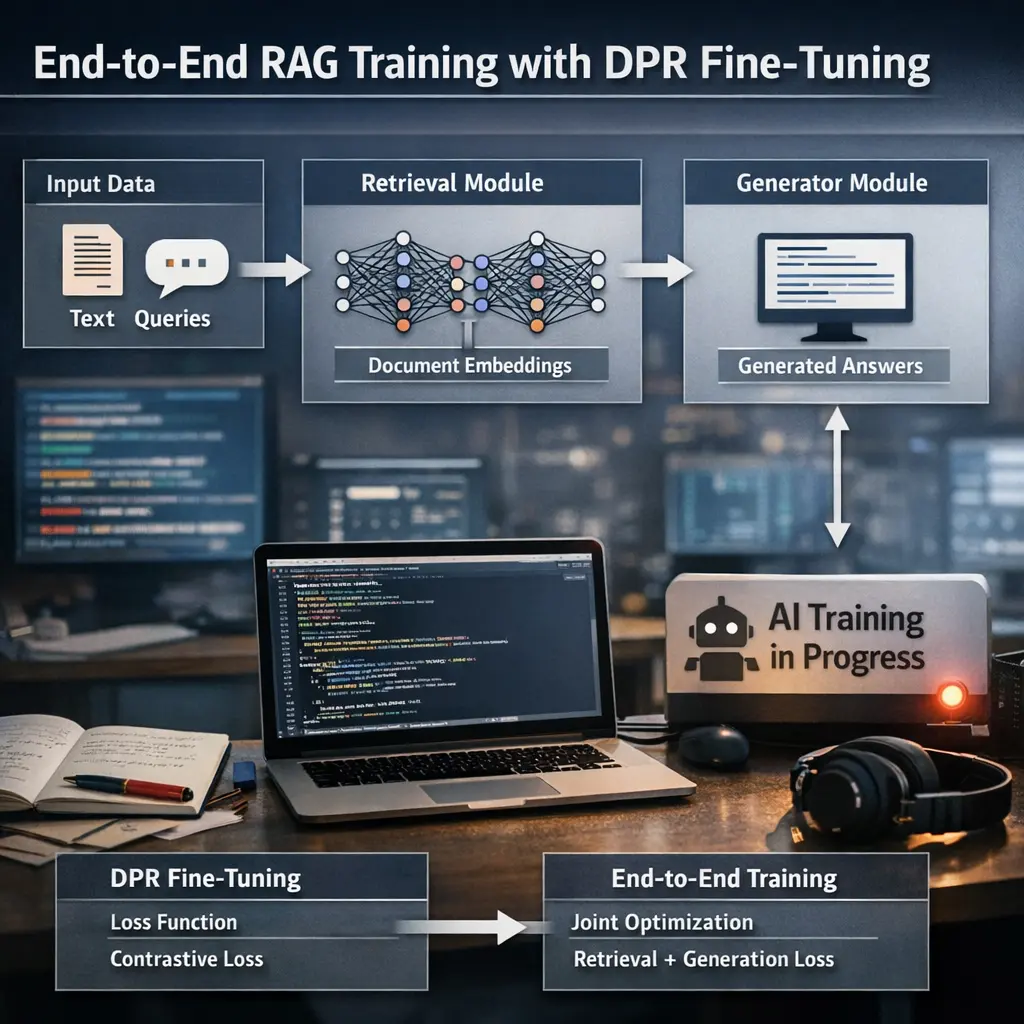
Dataset curation for domain knowledge bases using advanced Retrieval-Augmented Generation (RAG) techniques involves carefully selecting, organizing, and refining data sources to build specialized repositories tailored to specific fields or industries. Advanced RAG methods enhance this process by leveraging AI models to retrieve relevant information, filter out noise, and ensure high-quality, contextually appropriate content. This results in more accurate, efficient, and reliable knowledge bases that support sophisticated question-answering and decision-making tasks within targeted domains.
Dataset Curation for Domain Knowledge Bases
Dataset curation for domain knowledge bases using advanced Retrieval-Augmented Generation (RAG) techniques involves carefully selecting, organizing, and refining data sources to build specialized repositories tailored to specific fields or industries. Advanced RAG methods enhance this process by leveraging AI models to retrieve relevant information, filter out noise, and ensure high-quality, contextually appropriate content. This results in more accurate, efficient, and reliable knowledge bases that support sophisticated question-answering and decision-making tasks within targeted domains.

💡 Key Takeaways
- Identify data sources and selection criteria for domain knowledge bases.
- Apply consistent annotation and labeling standards for reliable knowledge extraction.
- Validate data quality with checks for accuracy, deduplication, and domain coverage.
- Manage metadata, provenance, versioning, and documentation for reproducibility.
- Address bias, privacy, and regulatory compliance in dataset curation.
❓ Frequently Asked Questions
What is dataset curation for domain knowledge bases?
Dataset curation involves collecting, cleaning, organizing, and validating data so a domain knowledge base can reliably store facts, relationships, and rules for a specific field.
What makes a dataset suitable for a domain knowledge base?
Relevance to the domain, accuracy, completeness, consistency, up-to-date information, and clear provenance and licensing.
What are common steps in dataset curation?
Collect data from trusted sources, remove duplicates, normalize formats and terms, annotate and align with the domain schema, tag provenance, and assess quality.
How do you ensure quality and trust in a domain knowledge base dataset?
Implement validation checks, maintain provenance records, perform reviews, evaluate coverage and precision/recall, and monitor for bias or outdated information.