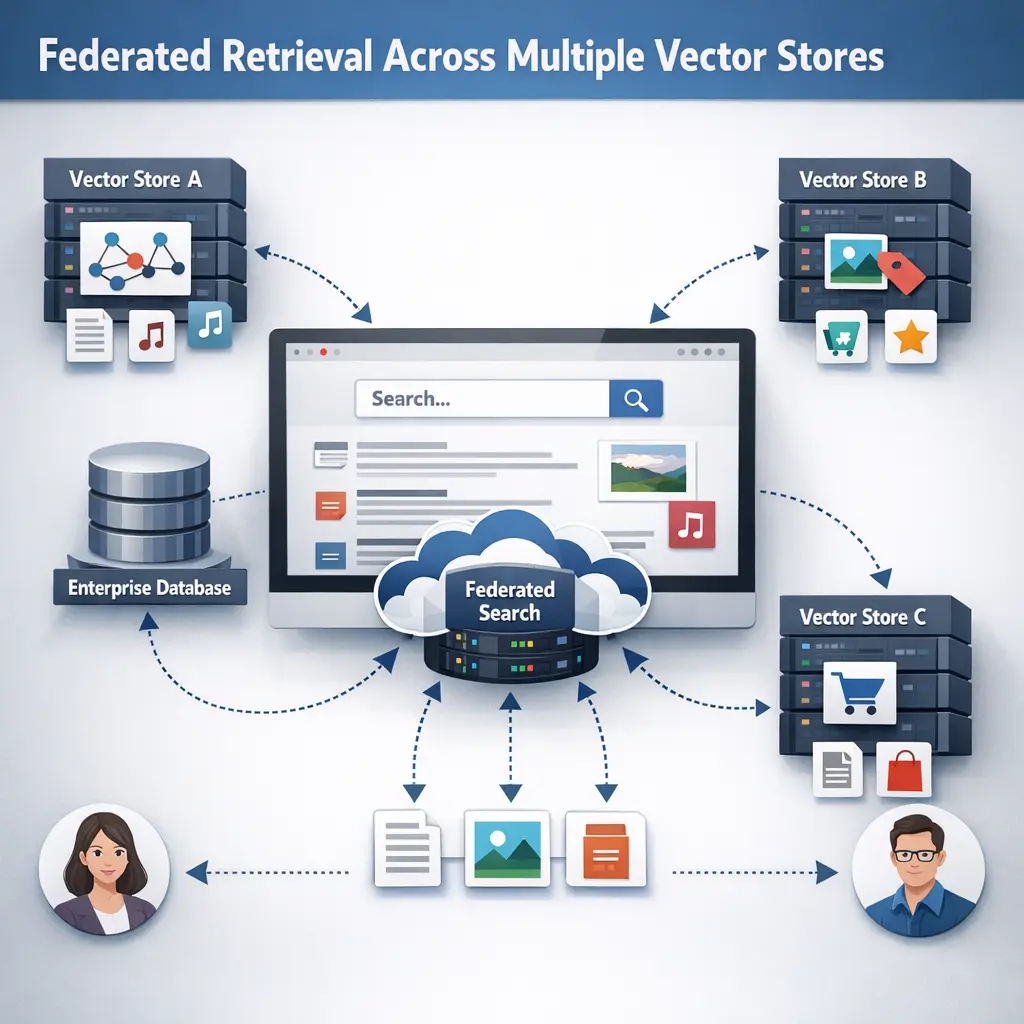
Federated Retrieval across Multiple Vector Stores in Retrieval-Augmented Generation (RAG) refers to a system where queries are distributed across several independent vector databases to retrieve relevant information. These results are then aggregated and used to enhance the generation of responses. This approach improves coverage, accuracy, and robustness by leveraging diverse data sources, enabling richer and more contextually relevant outputs in generative AI applications.
Federated Retrieval across Multiple Vector Stores
Federated Retrieval across Multiple Vector Stores in Retrieval-Augmented Generation (RAG) refers to a system where queries are distributed across several independent vector databases to retrieve relevant information. These results are then aggregated and used to enhance the generation of responses. This approach improves coverage, accuracy, and robustness by leveraging diverse data sources, enabling richer and more contextually relevant outputs in generative AI applications.
💡 Key Takeaways
- Understand the concept of federated retrieval across multiple vector stores and why it helps across data silos
- Learn query routing, cross-store result fusion, and ranking techniques to produce unified results
- Identify interoperability challenges such as schema alignment and embedding compatibility across stores
- Recognize privacy, security, and governance considerations when performing federated retrieval across data sources
❓ Frequently Asked Questions
What is federated retrieval across multiple vector stores?
A retrieval approach that queries several independent vector stores, each with its own embeddings, and combines the results into a single, ranked list without centralizing all data.
Why use federated retrieval instead of a single vector store?
To access data that resides in silos, preserve data locality and privacy, and enable scalable search across diverse sources without moving all data to one place.
How are results merged and ranked across stores?
Scores from each store are normalized and fused (e.g., score fusion or re-ranking), duplicates are removed, and a unified top-k list is produced.
What are common challenges in federated retrieval and how can they be addressed?
Challenges include latency, heterogeneous embeddings, access controls, and privacy. Solutions: query routing, caching, standardized interfaces, metadata filters, and privacy-preserving protocols.
What are typical use cases for federated retrieval across multiple vector stores?
Enterprise knowledge search across departmental silos, cross-domain research across repositories, and privacy-preserving search over restricted data stores.



