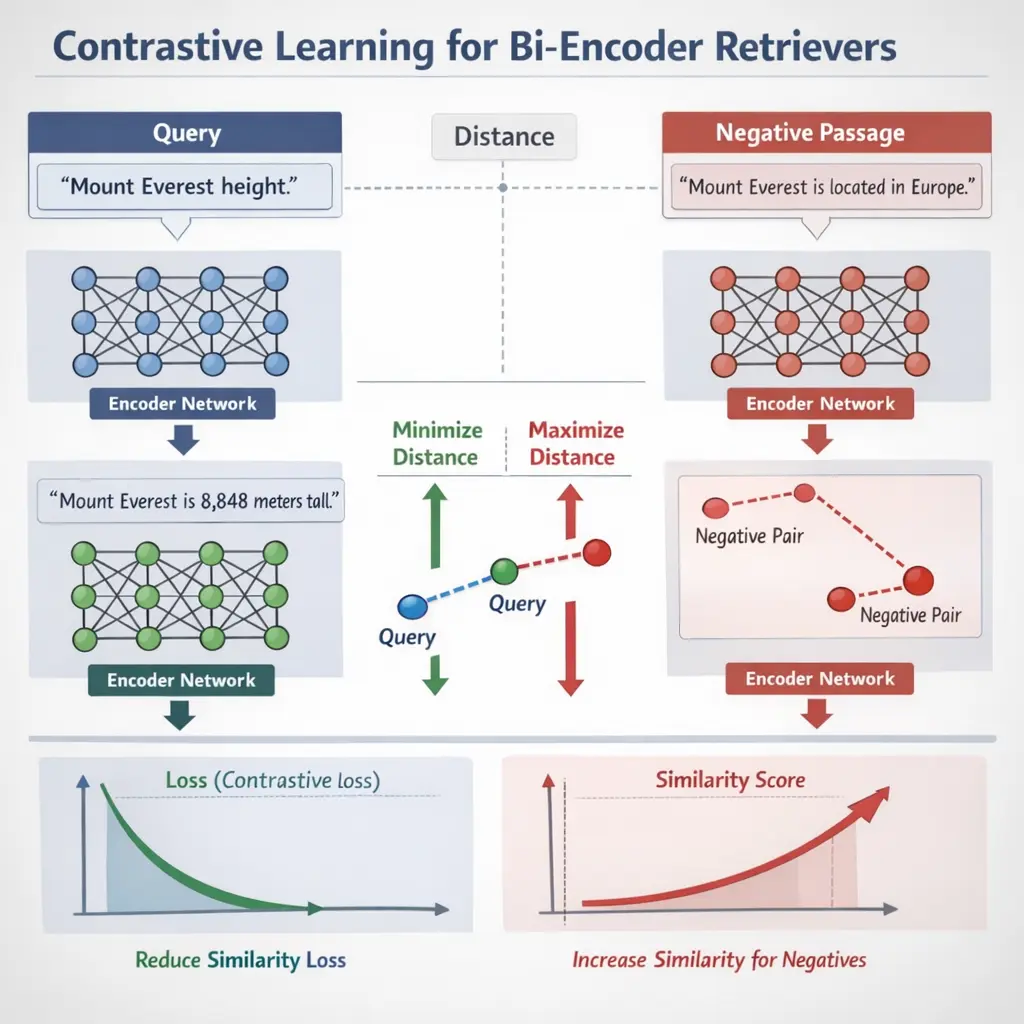
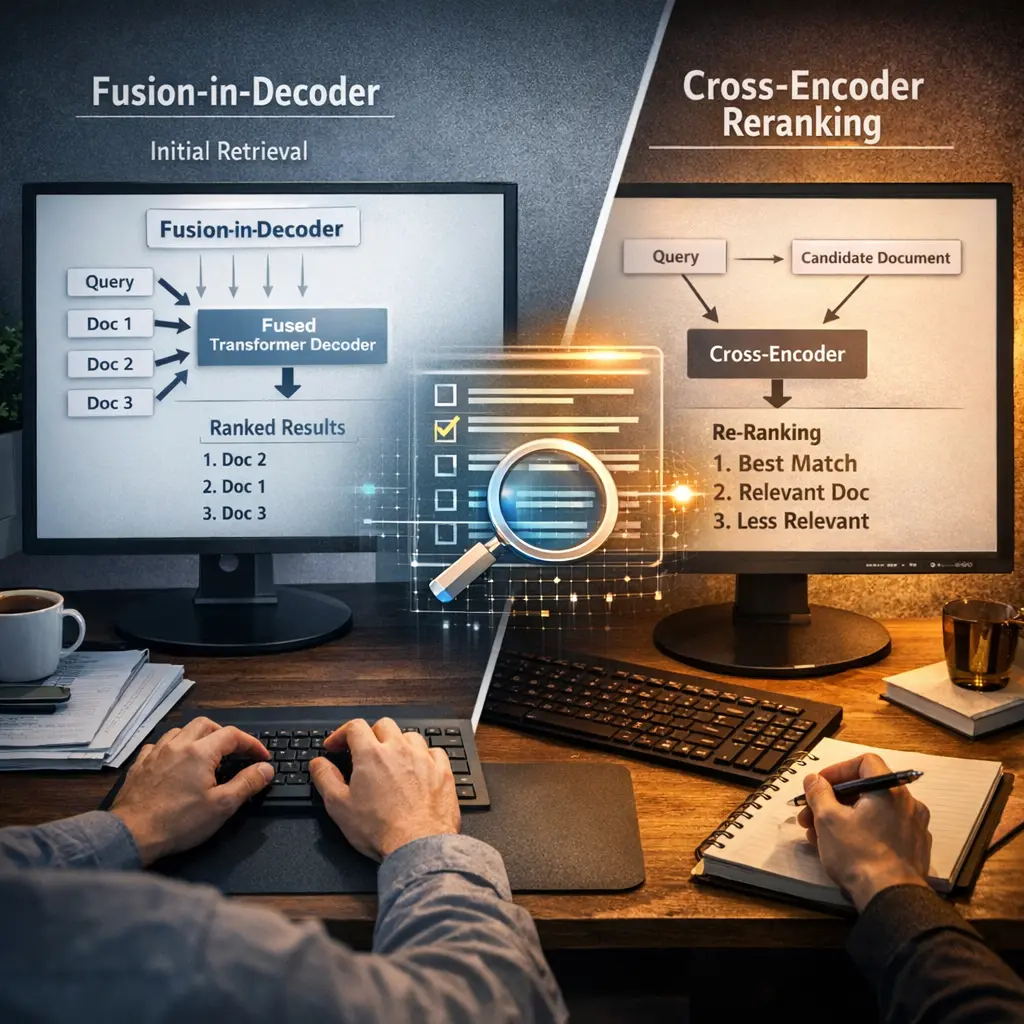
Fusion-in-Decoder and Cross-Encoder Reranking are advanced Retrieval-Augmented Generation (RAG) techniques. Fusion-in-Decoder combines retrieved documents within the decoder, allowing the model to jointly attend to multiple sources for more informed generation. Cross-Encoder Reranking involves using a cross-encoder model to score and reorder retrieved documents based on their relevance to the query, improving the quality of the final answer by prioritizing the most pertinent information sources.
Fusion-in-Decoder & Cross-Encoder Reranking
Fusion-in-Decoder and Cross-Encoder Reranking are advanced Retrieval-Augmented Generation (RAG) techniques. Fusion-in-Decoder combines retrieved documents within the decoder, allowing the model to jointly attend to multiple sources for more informed generation. Cross-Encoder Reranking involves using a cross-encoder model to score and reorder retrieved documents based on their relevance to the query, improving the quality of the final answer by prioritizing the most pertinent information sources.
💡 Key Takeaways
- Understand Fusion-in-Decoder (FiD) and how retrieved passages are fused into the decoder to generate answers.
- Learn how Cross-Encoder reranking scores candidate documents by jointly encoding the query and each document for higher ranking accuracy.
- Compare FiD and Cross-Encoder reranking: strengths, limitations, and when to apply each in retrieval-augmented QA or search pipelines.
- Outline a practical workflow from retrieval to reranking and learn common evaluation metrics (e.g., NDCG, MRR) and quick tips.
❓ Frequently Asked Questions
What is Fusion-in-Decoder (FiD)?
Fusion-in-Decoder is a retrieval-augmented generation method where a decoder generates answers by attending to a fused representation that combines the query with multiple retrieved documents.
What is cross-encoder reranking?
A cross-encoder is a model that encodes a query and a candidate document together to produce a relevance score. Reranking uses these scores to reorder retrieved documents by predicted relevance.
How do FiD and cross-encoder reranking differ?
FiD is a generative approach that uses multiple documents to produce an answer, while cross-encoder reranking is a discriminative scoring step to rank candidate documents. They serve different stages in an open-domain QA pipeline.
When should I use FiD vs cross-encoder reranking?
Use FiD when you want to generate an answer from multiple sources. Use cross-encoder reranking when you want to improve the quality of retrieved candidates by ordering them based on query relevance.