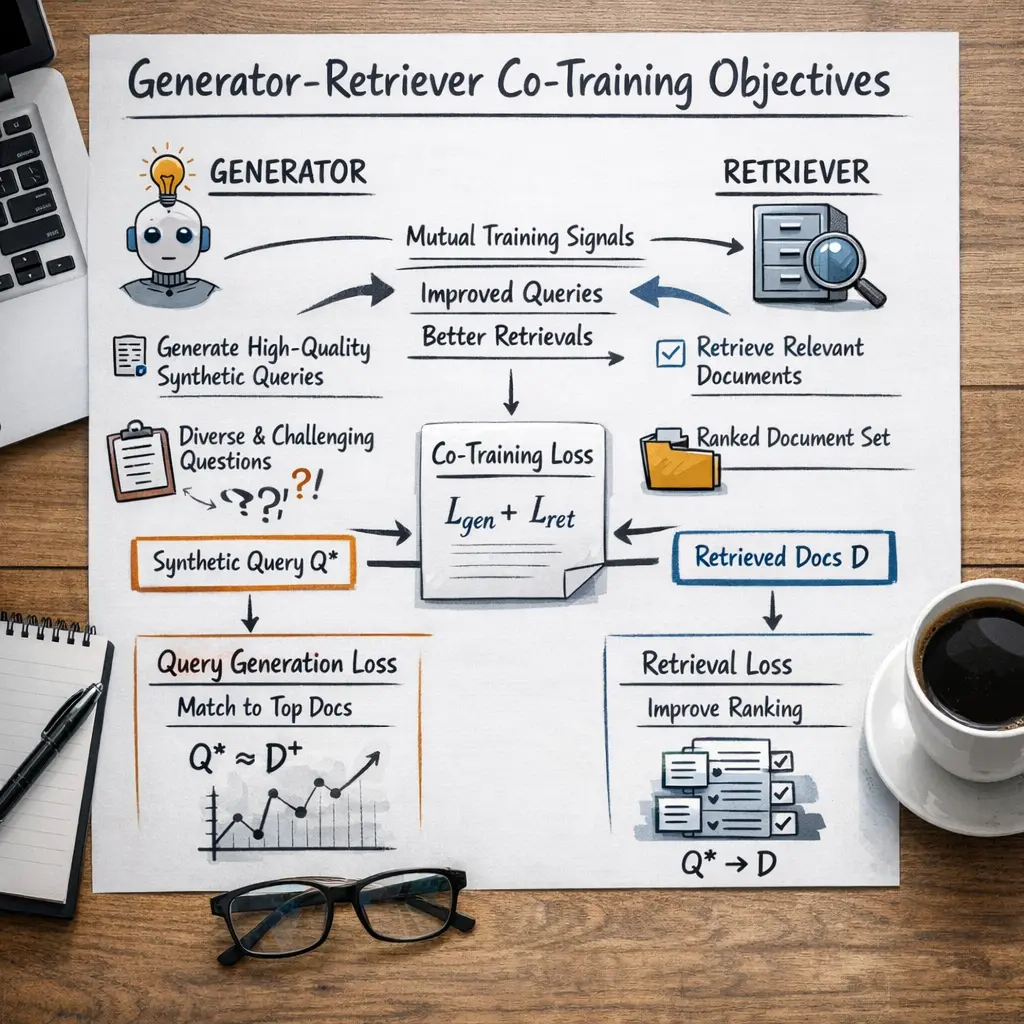
Generator-Retriever Co-Training Objectives in advanced Retrieval-Augmented Generation (RAG) techniques refer to jointly optimizing both the retriever (which selects relevant documents) and the generator (which formulates responses) during training. This approach ensures that the retriever provides context most useful for the generator, and the generator learns to best utilize retrieved content, resulting in improved end-to-end performance and more accurate, contextually appropriate responses in information-seeking tasks.
Generator-Retriever Co-Training Objectives
Generator-Retriever Co-Training Objectives in advanced Retrieval-Augmented Generation (RAG) techniques refer to jointly optimizing both the retriever (which selects relevant documents) and the generator (which formulates responses) during training. This approach ensures that the retriever provides context most useful for the generator, and the generator learns to best utilize retrieved content, resulting in improved end-to-end performance and more accurate, contextually appropriate responses in information-seeking tasks.
💡 Key Takeaways
- Understand the idea of co-training a text generator with a retriever in a single training loop.
- Learn how generator and retriever losses are combined to align retrieved facts with generated content.
- Identify how retrieved documents guide generation and how generated outputs provide feedback to improve retrieval.
- Recognize common challenges, metrics, and best practices for evaluating and deploying generator-retriever systems.
❓ Frequently Asked Questions
What is Generator-Retriever Co-Training?
A training approach where a text generator and a document retriever are optimized together using a joint objective so the retriever fetches helpful documents and the generator uses them to produce accurate responses.
What do the generator and retriever do in this setup?
The retriever selects relevant documents for a given query, and the generator uses those documents to generate a response. They are trained to improve each other’s performance.
What losses are used in the co-training objective?
Common losses include the generator's cross-entropy loss for the produced text and a retrieval loss (such as contrastive or cross-entropy over candidate documents). A weighted combination forms the joint objective.
What are the benefits and challenges of this approach?
Benefits include improved factuality and better use of external knowledge. Challenges involve training stability, computational cost, and balancing the retriever and generator so one doesn’t dominate the other.
How is this evaluated?
Evaluate both components: retrieval metrics (e.g., recall@k, MRR) for the retriever and generation metrics (e.g., BLEU/ROUGE, exact match) for the output, plus end-to-end QA or factuality assessments.