"Intro to Reranking Pipelines (Advanced RAG Techniques)" refers to the process of improving retrieval-augmented generation (RAG) systems by reordering or reranking retrieved candidate documents or passages before generating a final response. By applying advanced reranking algorithms—often using neural networks or large language models—these pipelines enhance response relevance and accuracy, ensuring that the generative model works with the most contextually appropriate information. This technique significantly boosts the performance of RAG-based applications.
Intro to Reranking Pipelines
"Intro to Reranking Pipelines (Advanced RAG Techniques)" refers to the process of improving retrieval-augmented generation (RAG) systems by reordering or reranking retrieved candidate documents or passages before generating a final response. By applying advanced reranking algorithms—often using neural networks or large language models—these pipelines enhance response relevance and accuracy, ensuring that the generative model works with the most contextually appropriate information. This technique significantly boosts the performance of RAG-based applications.

💡 Key Takeaways
- Understand what a reranking pipeline is and how it reorders a list of candidate items to improve relevance.
- Differentiate between the initial candidate generation step and the subsequent reranking step in a retrieval or recommendation system.
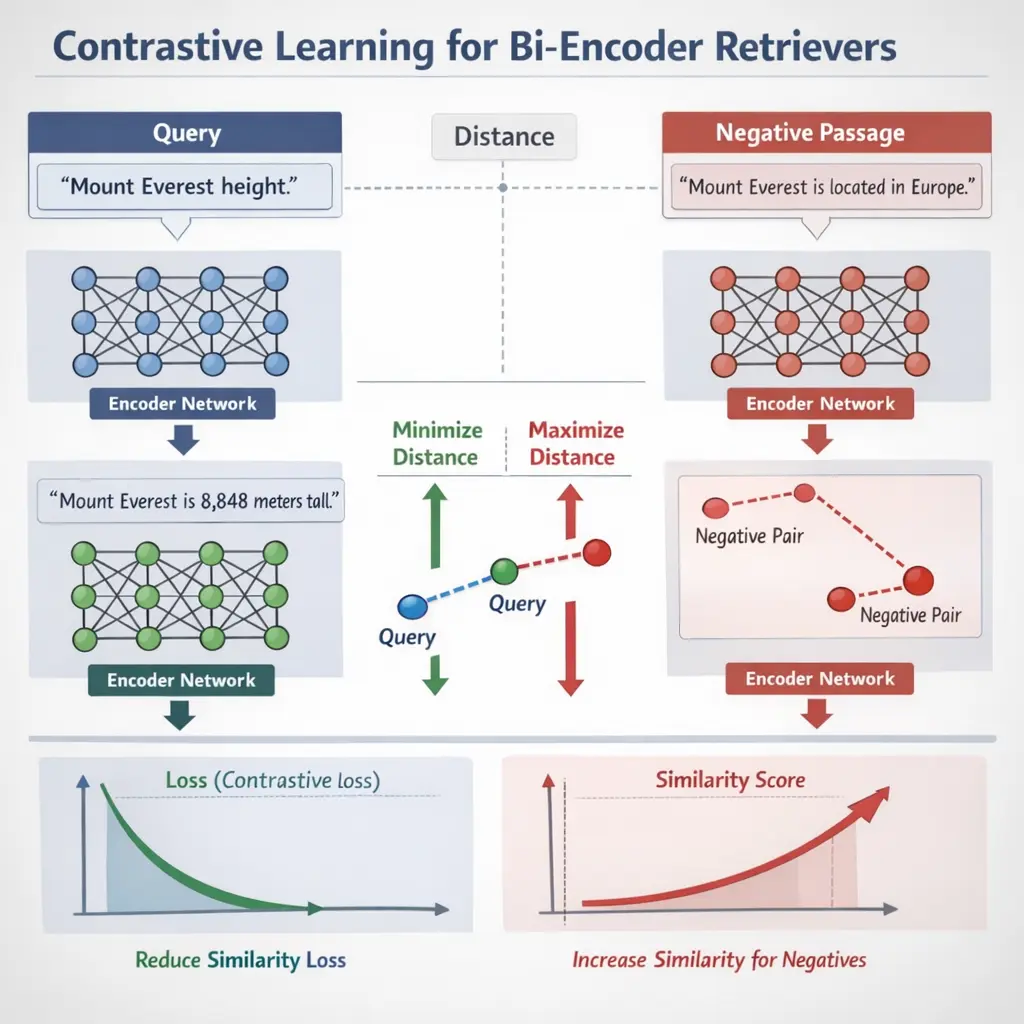
- Learn common reranking techniques (e.g., cross-encoder and bi-encoder models) and the types of features used (relevance signals, user context, metadata).
- Recognize how reranking affects accuracy vs. latency and what metrics (like NDCG or precision@k) are used to evaluate its impact.
❓ Frequently Asked Questions
What is a reranking pipeline?
A two-stage information retrieval setup: first a fast retriever grabs a small set of candidates, then a more powerful reranker reorders that subset to improve relevance.
How does reranking differ from the initial ranking step?
The initial ranking uses lightweight features to quickly score many items; the reranker uses heavier models and more features to refine the order on a smaller candidate set.
What models are commonly used for reranking?
Cross-encoder models that score query–item pairs jointly for high accuracy, and bi-encoder or neural re-rankers for better speed; learning-to-rank techniques are also common.
What metrics are used to evaluate a reranking system?
Ranking metrics such as NDCG, MAP, and precision@k, typically evaluated on a held-out set with attention to latency.