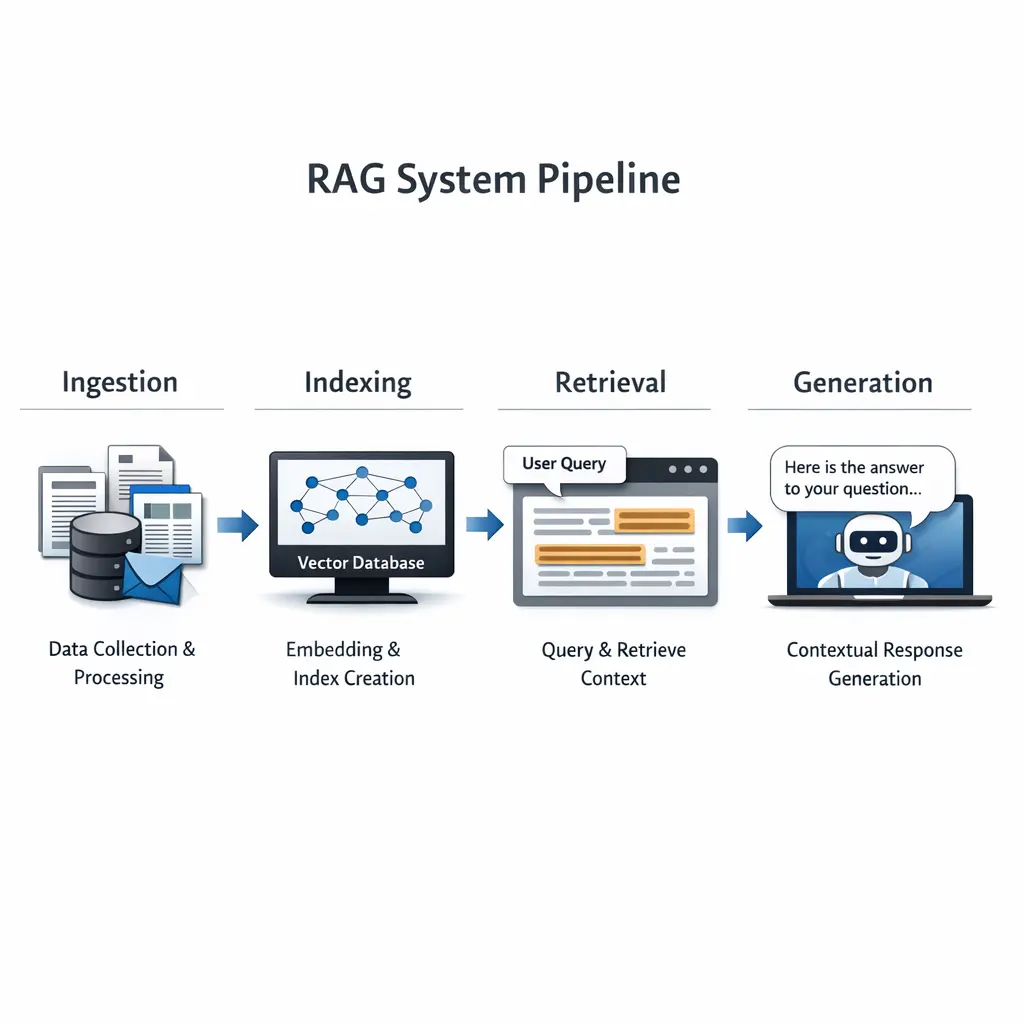
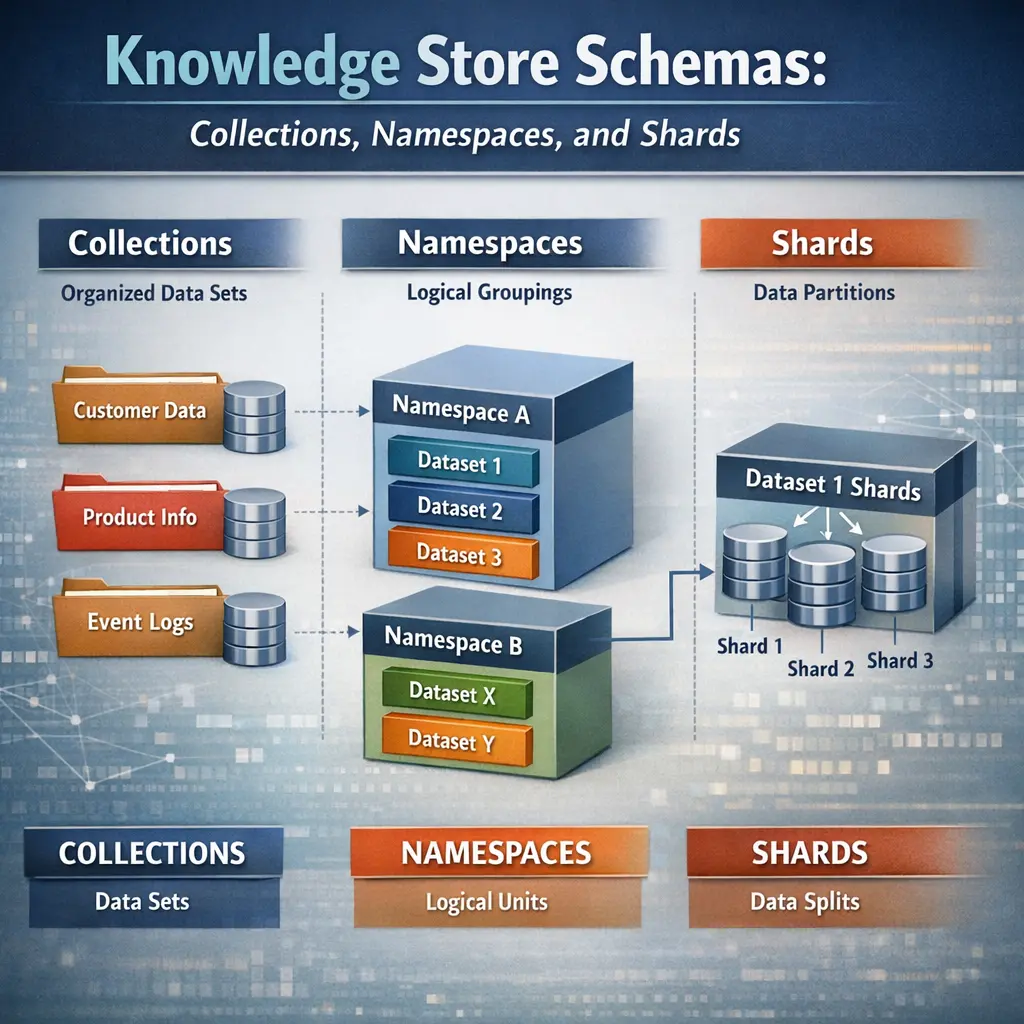
Knowledge Store Schemas in Retrieval-Augmented Generation (RAG) organize data using collections, namespaces, and shards. Collections group related documents, namespaces provide logical separation within the data, and shards divide large datasets for efficient storage and retrieval. This schema structure enables scalable, organized, and efficient access to knowledge sources, ensuring that retrieval processes in RAG systems are both fast and contextually relevant.
Knowledge Store Schemas: Collections, Namespaces, and Shards
Knowledge Store Schemas in Retrieval-Augmented Generation (RAG) organize data using collections, namespaces, and shards. Collections group related documents, namespaces provide logical separation within the data, and shards divide large datasets for efficient storage and retrieval. This schema structure enables scalable, organized, and efficient access to knowledge sources, ensuring that retrieval processes in RAG systems are both fast and contextually relevant.
💡 Key Takeaways
- Understand the purpose of knowledge store schemas and how collections, namespaces, and shards fit together.
- Distinguish between collections as logical groupings of items and namespaces as isolation contexts for data.
- Learn how sharding partitions data across servers to scale storage and queries, and how to select effective shard keys.
- Apply design best practices for naming, organization, and cross-shard querying to optimize performance.
❓ Frequently Asked Questions
What is a knowledge store schema?
A design that organizes knowledge items into logical units (collections), isolates data with namespaces, and distributes data across nodes with shards to improve access and scalability.
What is a collection in a knowledge store?
A collection is a container for related knowledge items (documents or records). It groups items by topic or function and defines common attributes.
What is a namespace in a knowledge store?
A namespace provides logical isolation so multiple tenants or environments can coexist without name conflicts; items live within their namespace.
What is a shard in a knowledge store?
A shard is a horizontal partition of data across multiple storage nodes, distributing a collection's items to improve throughput and scalability.
How do collections, namespaces, and shards relate?
Collections hold items, namespaces isolate groups or tenants, and shards partition data across nodes; used together to enable multi-tenant design and scalable access.