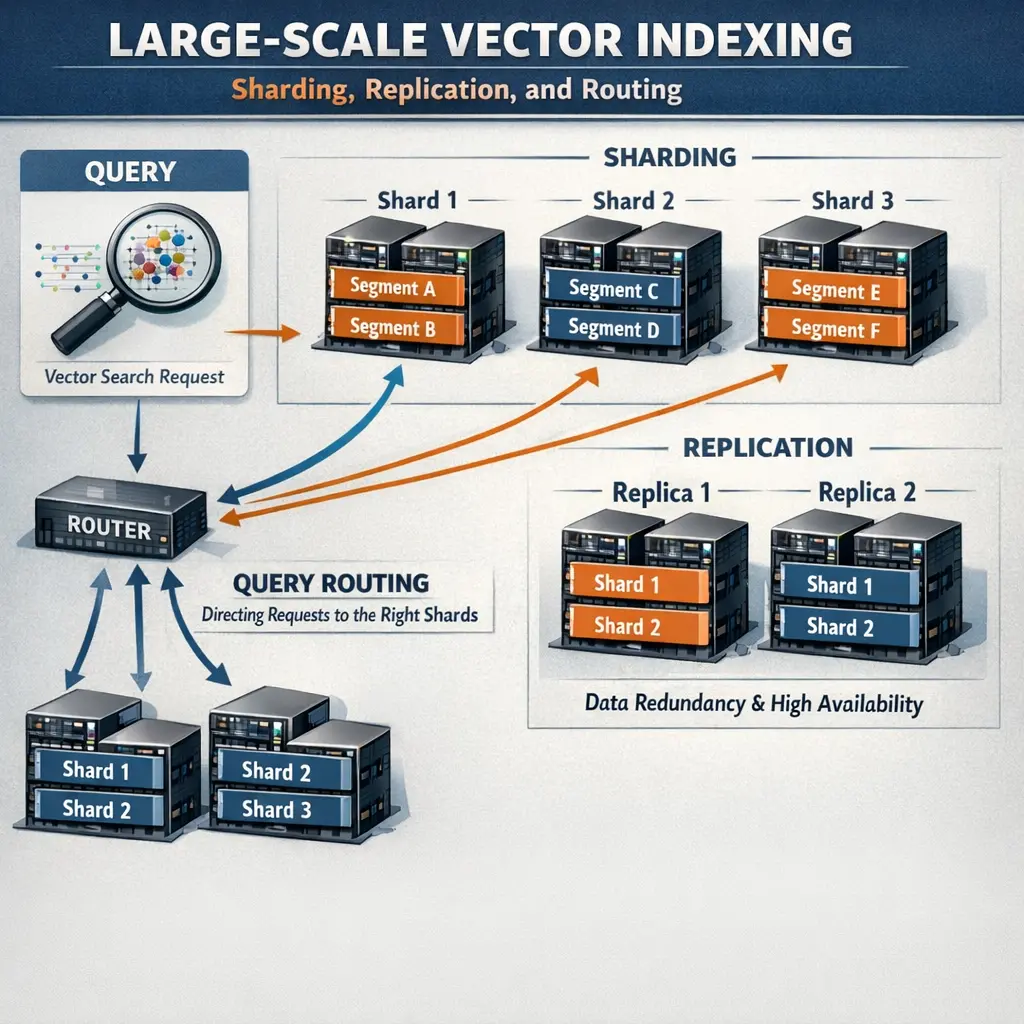
Large-scale vector indexing involves organizing vast collections of vector embeddings to enable efficient similarity search, crucial for Retrieval-Augmented Generation (RAG) systems. Sharding divides the dataset into manageable partitions distributed across multiple nodes, while replication creates copies to enhance fault tolerance and availability. Routing determines how queries are directed to the appropriate shard or replica, ensuring fast and accurate retrieval of relevant information. Together, these techniques enable scalable, reliable, and high-performance retrieval in RAG applications.
Large-Scale Vector Indexing: Sharding, Replication, and Routing
Large-scale vector indexing involves organizing vast collections of vector embeddings to enable efficient similarity search, crucial for Retrieval-Augmented Generation (RAG) systems. Sharding divides the dataset into manageable partitions distributed across multiple nodes, while replication creates copies to enhance fault tolerance and availability. Routing determines how queries are directed to the appropriate shard or replica, ensuring fast and accurate retrieval of relevant information. Together, these techniques enable scalable, reliable, and high-performance retrieval in RAG applications.
💡 Key Takeaways
- Understand how sharding partitions vectors across multiple nodes to enable horizontal scaling.
- Learn how replication creates redundant shard copies for fault tolerance and higher read throughput, with implications for write latency.
- Grasp routing strategies to direct queries to the right shards efficiently, including partition-aware routing and routing tables.
- Identify design trade-offs and operational considerations in large-scale vector indexing, such as consistency, rebalancing, and failure handling.
❓ Frequently Asked Questions
What is vector indexing and why is it used in large-scale search?
Vector indexing stores high-dimensional vectors and enables fast similarity search (ANN) to find items similar to a query vector.
What is sharding in a vector index?
Sharding partitions the index across multiple machines, so each shard holds a subset of vectors, enabling parallel processing and scalability.
What is replication in this context?
Replication creates copies of data on multiple nodes to improve fault tolerance and read throughput, ensuring data availability.
What is routing in a distributed vector index system?
Routing determines which shard(s) to query for a given vector or query and how to combine results from shards to produce final answers.