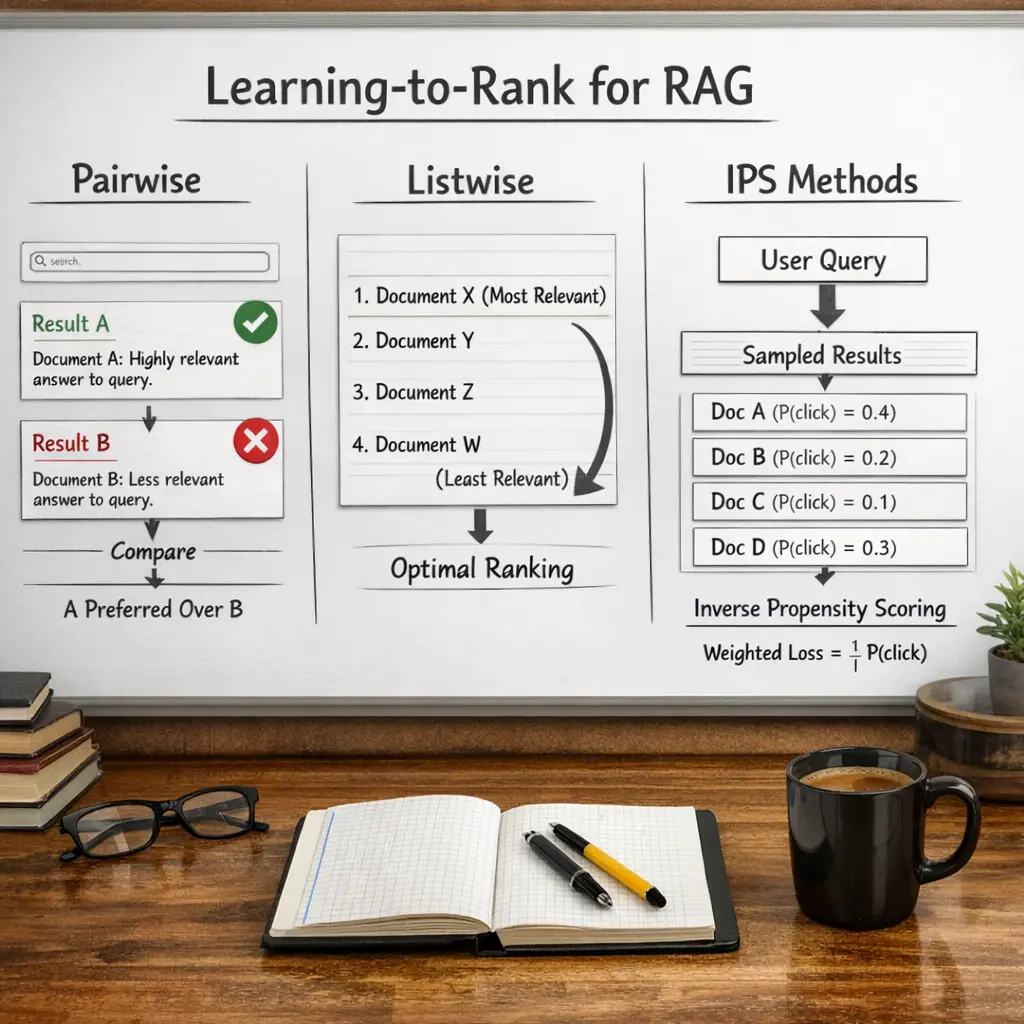
Learning-to-Rank for Retrieval-Augmented Generation (RAG) refers to optimizing how retrieved documents are ranked before being fed to a generative model. Pairwise methods compare document pairs to determine which is more relevant, while listwise methods consider the entire set of retrieved documents to optimize their overall ordering. Inverse Propensity Scoring (IPS) methods adjust for bias in training data, ensuring more accurate ranking. These approaches improve the relevance and quality of information provided to RAG systems.
Learning-to-Rank for RAG: Pairwise, Listwise, and IPS Methods
Learning-to-Rank for Retrieval-Augmented Generation (RAG) refers to optimizing how retrieved documents are ranked before being fed to a generative model. Pairwise methods compare document pairs to determine which is more relevant, while listwise methods consider the entire set of retrieved documents to optimize their overall ordering. Inverse Propensity Scoring (IPS) methods adjust for bias in training data, ensuring more accurate ranking. These approaches improve the relevance and quality of information provided to RAG systems.
💡 Key Takeaways
- Understand how learning-to-rank improves passage retrieval in a RAG system to boost answer quality.
- Differentiate pairwise and listwise ranking approaches and what they optimize.
- Learn how IPS (importance sampling) provides unbiased training signals for LTR in RAG.
- Identify practical considerations for evaluating and integrating LTR with generation models (e.g., ranking metrics and relevance labeling).
❓ Frequently Asked Questions
What is learning-to-rank (LTR) in the context of RAG?
LTR trains a model to order retrieved documents by relevance so the RAG system presents the most useful sources to the generator.
How do pairwise and listwise LTR approaches differ?
Pairwise learns from comparisons between two items to decide which is more relevant; listwise optimizes the entire candidate list using ranking metrics.
What is IPS (Inverse Propensity Scoring) and why is it used?
IPS reweights training signals by the inverse of their propensity (likelihood of being observed) to reduce biases in logged data when learning to rank.
How do these methods help in a RAG pipeline?
They shape how retrieved documents are ranked for the generator: pairwise/listwise define the optimization objective, and IPS helps debias training data from interactions.