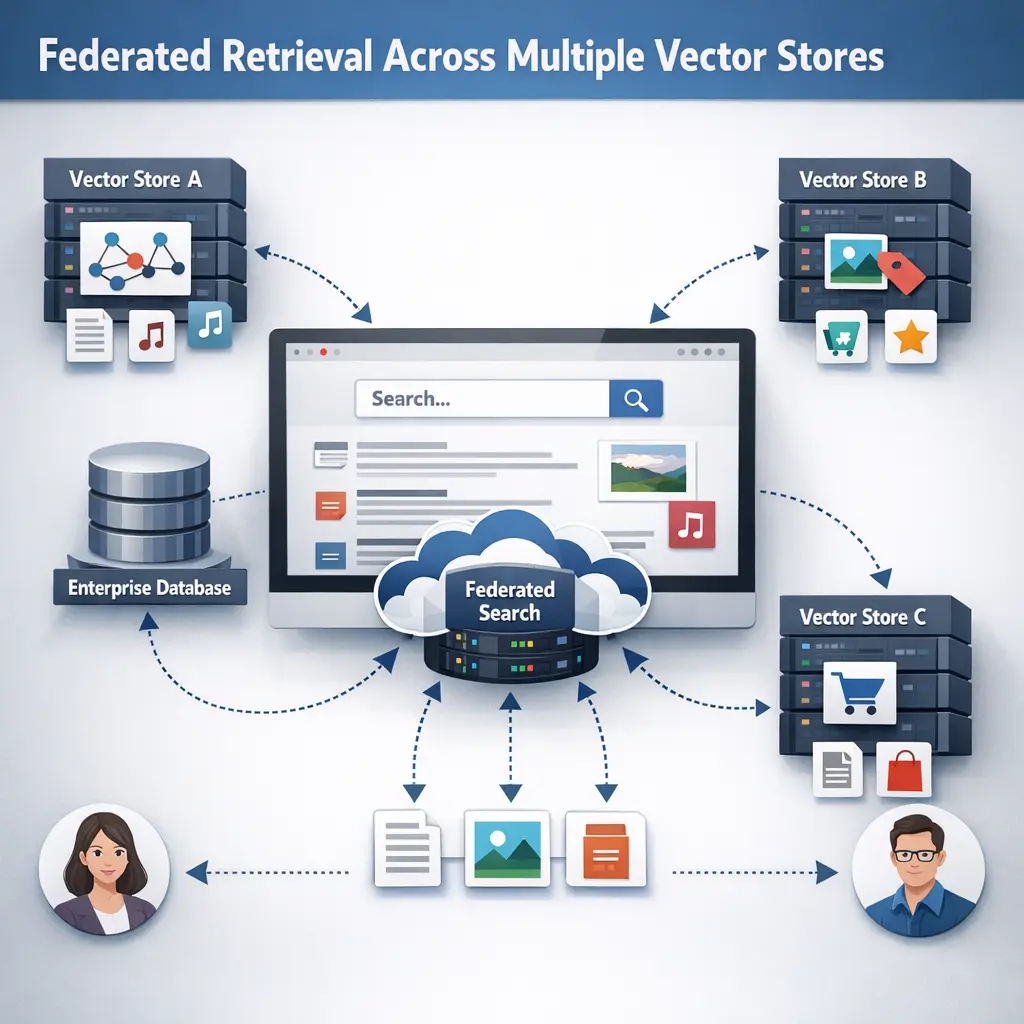
Mixture-of-Experts and Specialist Retriever Ensembles in Retrieval-Augmented Generation (RAG) refer to combining multiple retrievers or expert models, each specialized in different domains or tasks, to enhance information retrieval. During generation, the system dynamically selects the most relevant experts or retrievers based on the input query. This approach improves accuracy, relevance, and robustness of generated responses by leveraging diverse expertise and retrieving more pertinent context for the language model.
Mixture-of-Experts and Specialist Retriever Ensembles
Mixture-of-Experts and Specialist Retriever Ensembles in Retrieval-Augmented Generation (RAG) refer to combining multiple retrievers or expert models, each specialized in different domains or tasks, to enhance information retrieval. During generation, the system dynamically selects the most relevant experts or retrievers based on the input query. This approach improves accuracy, relevance, and robustness of generated responses by leveraging diverse expertise and retrieving more pertinent context for the language model.

💡 Key Takeaways
- Understand what a Mixture-of-Experts (MoE) model is and how a gating network routes inputs to specialized experts.
- Learn how Specialist Retriever Ensembles combine domain-specific retrievers to improve relevance and coverage.
- Grasp the benefits of MoE and specialist ensembles, including efficiency, scalability, and improved performance on diverse data.
- Be aware of common challenges such as training complexity, gating accuracy, and preventing underutilization of experts.
❓ Frequently Asked Questions
What is a Mixture-of-Experts (MoE) model?
An MoE model uses a gating network to route inputs to a small subset of specialized sub-models (experts), enabling a large overall capacity with sparse activation.
How does the gating network decide which experts to use?
The gating network assigns weights to each expert for a given input; only the top-weighted experts contribute to the output, making the routing sparse.
What is a Specialist Retriever Ensemble?
A specialist retriever ensemble combines multiple retrievers, each trained to excel in a particular domain or item type, to improve overall retrieval quality.
How are MoE and specialist retriever ensembles related or different?
MoE routes inputs to different model experts to grow capacity efficiently, while specialist retriever ensembles combine multiple retrieval components for better results; they can be used together by routing across retrievers.
What are common challenges when using MoE or specialist ensembles?
Challenges include training stability, effective load balancing among experts, ensuring coverage of data for all experts, and managing inference costs despite sparse activation.