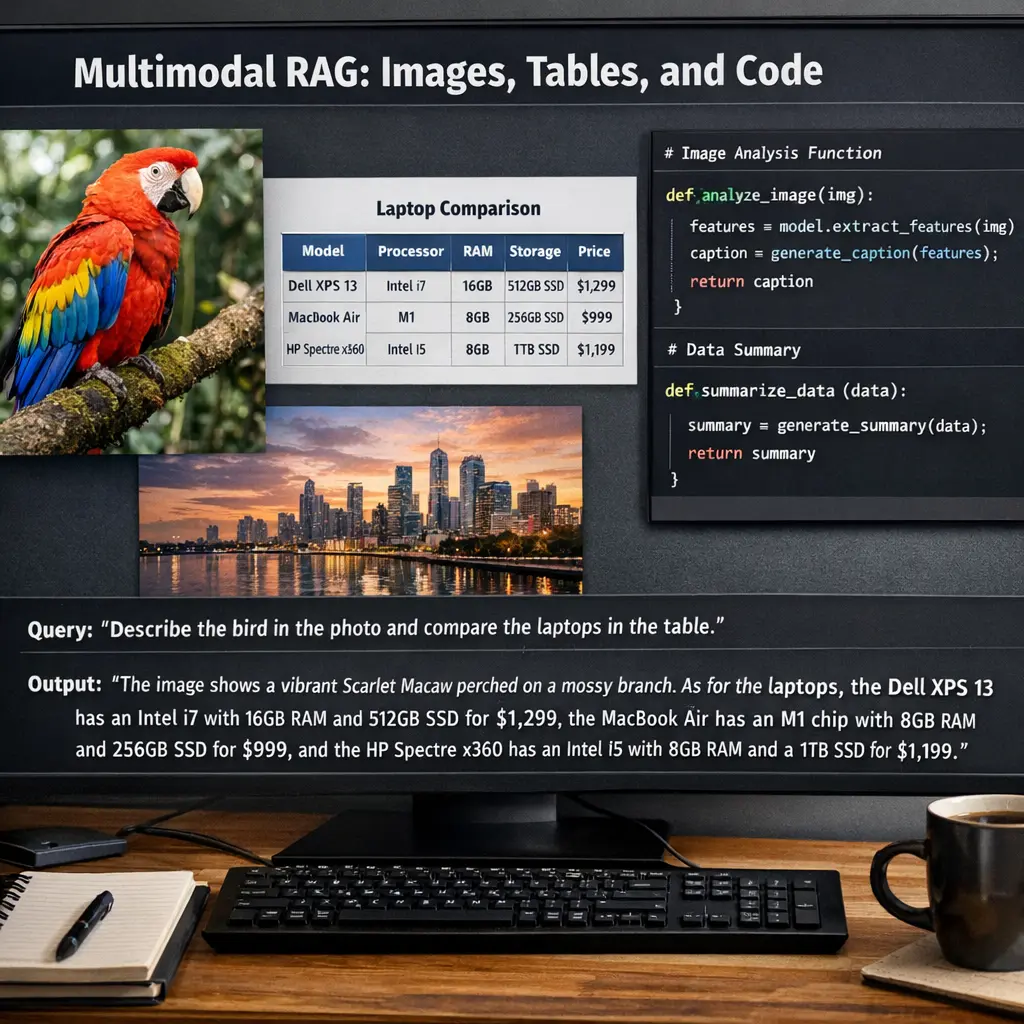
Multimodal RAG refers to advanced Retrieval-Augmented Generation techniques that integrate multiple data types—such as images, tables, and code—into the retrieval and generation process. By combining textual, visual, and structured data, multimodal RAG systems can provide richer, more context-aware responses. This approach enhances model capabilities in tasks like answering complex queries, interpreting visual content, and executing code, making AI interactions more versatile and effective across diverse information formats.
Multimodal RAG: Images, Tables, and Code
Multimodal RAG refers to advanced Retrieval-Augmented Generation techniques that integrate multiple data types—such as images, tables, and code—into the retrieval and generation process. By combining textual, visual, and structured data, multimodal RAG systems can provide richer, more context-aware responses. This approach enhances model capabilities in tasks like answering complex queries, interpreting visual content, and executing code, making AI interactions more versatile and effective across diverse information formats.
💡 Key Takeaways
- Understand what multimodal RAG is and why images, tables, and code can improve retrieval and answer generation.
- Learn how to encode and combine visual, tabular, and code data in a multimodal RAG pipeline.
- Identify common challenges such as alignment, grounding, and uncertainty, and strategies to mitigate them.
- Apply evaluation criteria to assess the accuracy, relevance, and reproducibility of multimodal RAG outputs.
❓ Frequently Asked Questions
What is Multimodal RAG?
Multimodal Retrieval-Augmented Generation combines retrieved content from multiple data types (images, tables, and code) with generated text to answer questions or explain concepts.
How does Multimodal RAG use images?
It uses visual features and captions from relevant images to supplement context, enabling visuals-aware answers and visual question-answering.
How are tables processed in Multimodal RAG?
Tables are parsed into structured data (rows and columns) and used to fetch precise facts or summaries, which are merged into the final response.
How is code handled in Multimodal RAG?
Code snippets from relevant sources are retrieved and incorporated, allowing explanations, debugging help, or generated code with proper context.
What should you watch for when using Multimodal RAG?
Be mindful of reliability and potential hallucinations; verify data from images, tables, and code, and ensure privacy and licensing considerations for sources.



