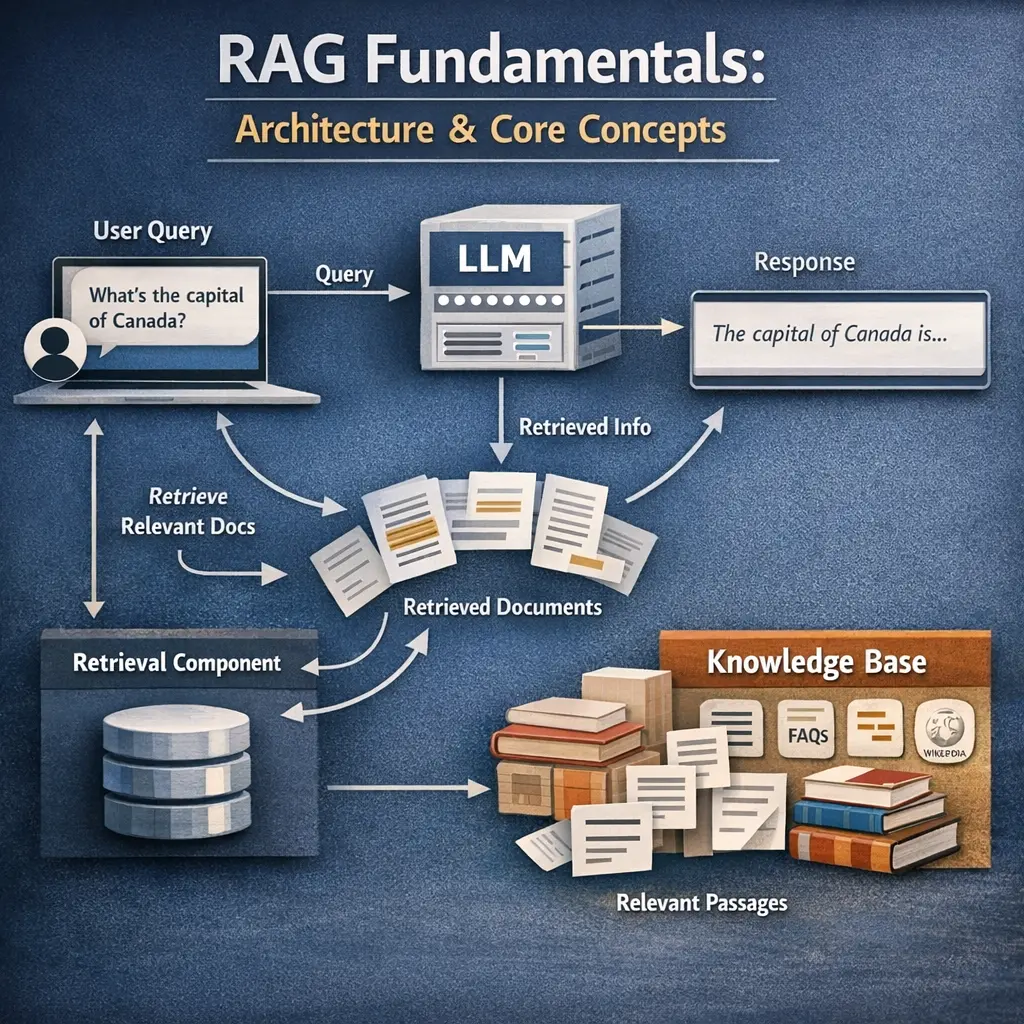
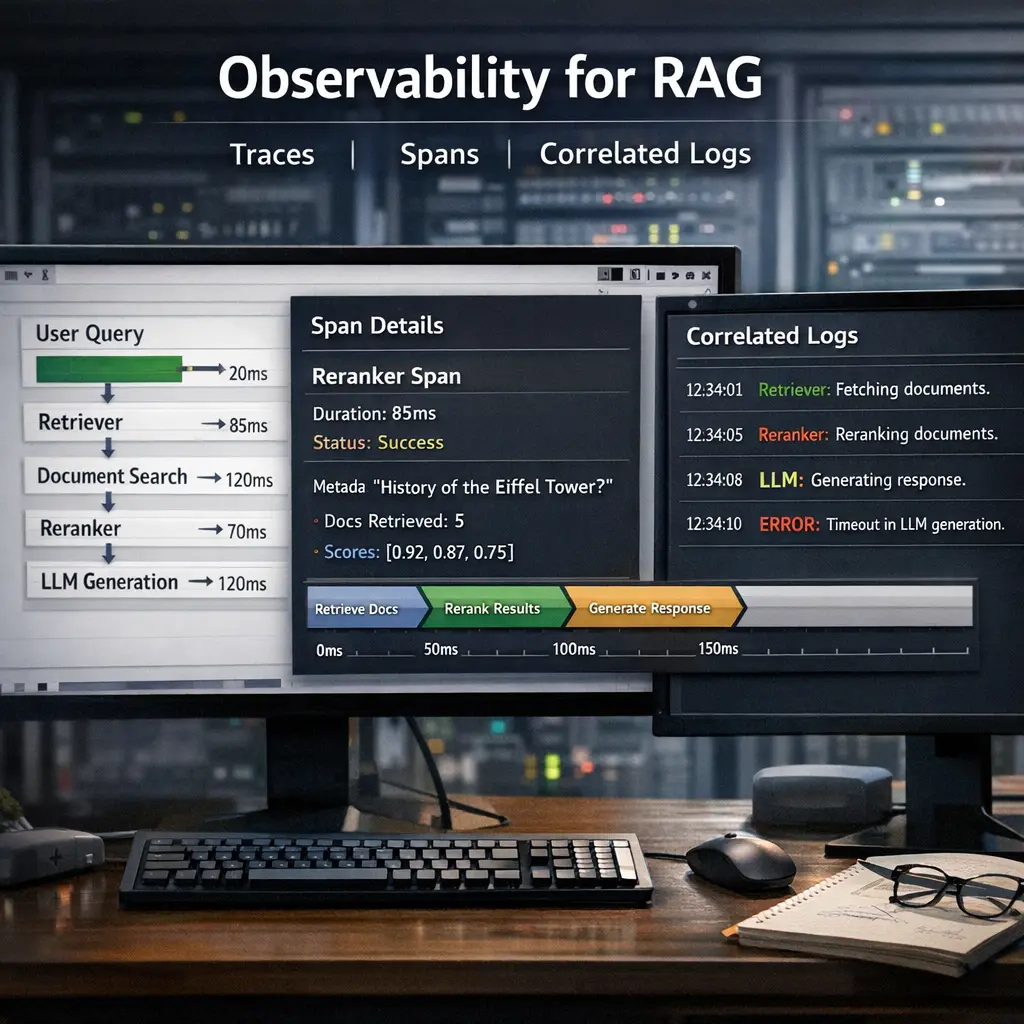
Observability for RAG involves monitoring and analyzing the end-to-end workflow of Retrieval-Augmented Generation systems. Using traces and spans, engineers can track each step—such as document retrieval and response generation—within a request. Correlated logs provide detailed, contextual information about events and errors as they occur. Together, these tools help diagnose issues, optimize performance, and ensure reliability by making complex interactions within RAG pipelines transparent and understandable.
Observability for RAG: Traces, Spans, and Correlated Logs
Observability for RAG involves monitoring and analyzing the end-to-end workflow of Retrieval-Augmented Generation systems. Using traces and spans, engineers can track each step—such as document retrieval and response generation—within a request. Correlated logs provide detailed, contextual information about events and errors as they occur. Together, these tools help diagnose issues, optimize performance, and ensure reliability by making complex interactions within RAG pipelines transparent and understandable.
💡 Key Takeaways
- Understand end-to-end observability of a RAG pipeline by mapping traces, spans, and correlated logs from input to answer.
- Learn how to instrument prompts, retrieval calls, and generation steps with spans to measure latency and detect failures.
- Learn to correlate logs across components (retriever, ranker, generator) to quickly pinpoint root causes.
- Identify key observability metrics and best practices for RAG systems, such as latency, error rates, throughput, and trace context for debugging.
❓ Frequently Asked Questions
What is observability in the context of RAG?
Observability is the ability to understand how a retrieval-augmented generation (RAG) system behaves by collecting traces, logs, and metrics from its components. This helps you debug, optimize latency and accuracy, and trust the results.
What are traces and spans in observability?
A trace represents the end-to-end journey of a single user query across components (retriever, document store, reranker, generator). A span is a single operation within that journey (e.g., a call to the retriever) with start/end times and metadata.
What are correlated logs and why are they useful?
Logs are timestamped events. Correlated logs include identifiers like trace IDs or request IDs, which let you stitch events across services to reconstruct the full flow of a query and diagnose issues.
How does tracing improve RAG performance and reliability?
Tracing helps you identify slow components, failures, or data bottlenecks in the retrieval and generation pipeline, enabling targeted optimizations, alerting, and more predictable latency and quality.