Retrieval-Augmented Generation (RAG) for scientific workflows and data-intensive domains is an AI approach that combines large language models with external data retrieval. It enables systems to access and integrate up-to-date, domain-specific information from scientific literature, databases, or datasets during text generation. This enhances the accuracy, reliability, and relevance of responses or analyses, making RAG particularly valuable for complex scientific research, data analysis, and knowledge discovery in fields that require current, evidence-based information.
RAG for Scientific Workflows and Data-Intensive Domains
Retrieval-Augmented Generation (RAG) for scientific workflows and data-intensive domains is an AI approach that combines large language models with external data retrieval. It enables systems to access and integrate up-to-date, domain-specific information from scientific literature, databases, or datasets during text generation. This enhances the accuracy, reliability, and relevance of responses or analyses, making RAG particularly valuable for complex scientific research, data analysis, and knowledge discovery in fields that require current, evidence-based information.

💡 Key Takeaways
- Explain what Retrieval-Augmented Generation (RAG) is and why it helps scientific workflows and data-heavy domains.
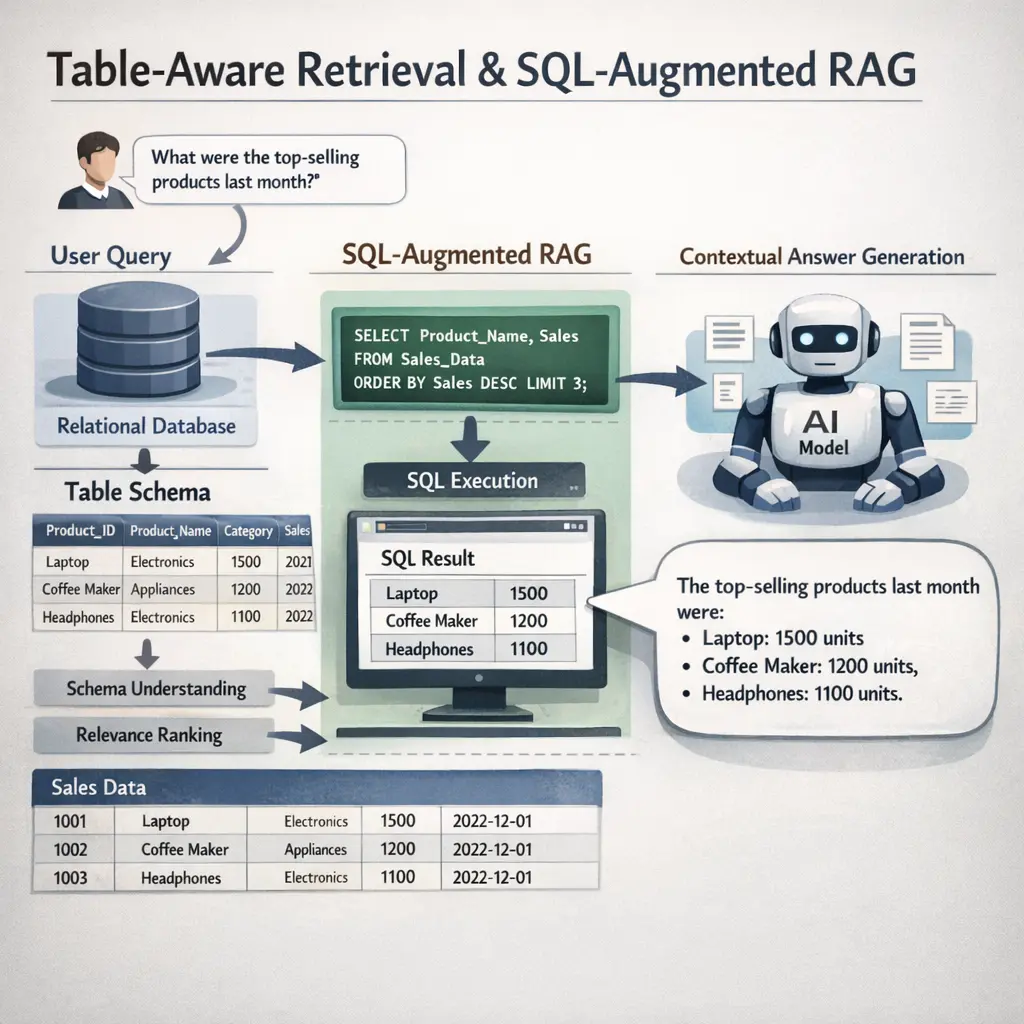
- Learn how to wire retrieval sources (papers, datasets, code) to generation steps to create accurate, provenance-backed outputs.
- Explore practical RAG use cases for science: automating literature reviews, summarizing datasets, and documenting experiments.
- Understand key challenges and best practices for RAG in science, including data quality, hallucination mitigation, and provenance tracking.
❓ Frequently Asked Questions
What is Retrieval-Augmented Generation (RAG) in simple terms?
RAG combines a document retriever with a language generator. It fetches relevant sources and uses them to produce answers or summaries, grounding the output in external material rather than relying solely on memory.
How does RAG apply to scientific workflows?
In scientific workflows, RAG can summarize methods, justify decisions, or generate reports by pulling from papers, datasets, and workflow logs, helping outputs cite sources and reflect current data.
What are data-intensive domains, and why use RAG there?
Data-intensive domains (e.g., genomics, climate science, materials science) involve vast datasets. RAG helps reason over diverse sources, produce evidence-backed results, and retrieve relevant information as new data arrive.
What are the main components of a RAG system?
Key parts are a retriever (to fetch relevant documents), a generator (to synthesize answers), and a data store or index (to organize source materials). An optional reader and provenance tooling can improve accuracy and traceability.
What are common challenges when using RAG for scientific work?
Challenges include potential hallucinations, source reliability, data access and licensing, latency and cost, and ensuring reproducibility and proper attribution of cited materials.