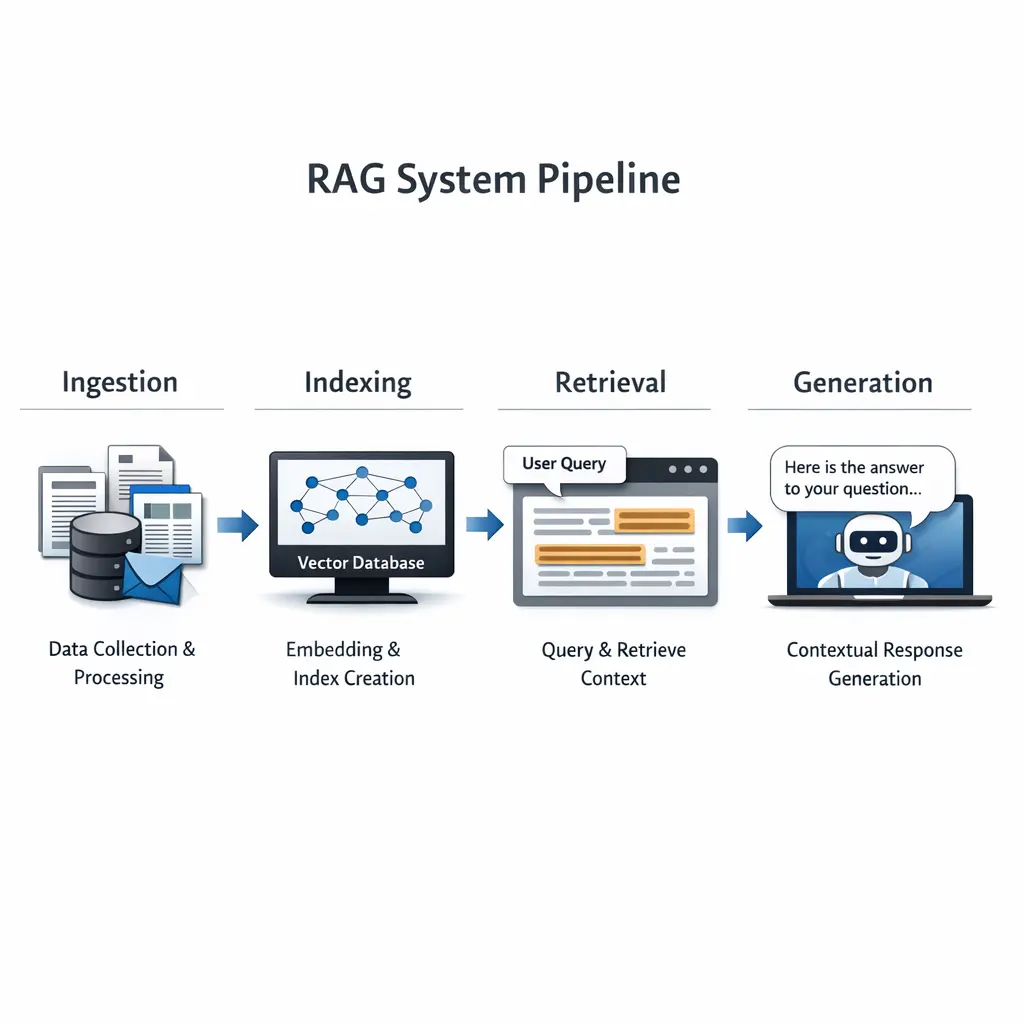
The RAG System Pipeline is a process used in Retrieval-Augmented Generation models. It involves four key stages: Ingestion, where data is collected and processed; Indexing, where the data is organized for efficient searching; Retrieval, where relevant information is fetched in response to a query; and Generation, where an AI model combines retrieved data with its own capabilities to create accurate, context-rich responses. This approach enhances the quality and relevance of generated outputs.
RAG System Pipeline: Ingestion, Indexing, Retrieval, Generation
The RAG System Pipeline is a process used in Retrieval-Augmented Generation models. It involves four key stages: Ingestion, where data is collected and processed; Indexing, where the data is organized for efficient searching; Retrieval, where relevant information is fetched in response to a query; and Generation, where an AI model combines retrieved data with its own capabilities to create accurate, context-rich responses. This approach enhances the quality and relevance of generated outputs.
💡 Key Takeaways
- Understand the end-to-end RAG pipeline: ingestion, indexing, retrieval, and generation, and how they connect to answering questions.
- Learn how data is ingested and prepared (cleansing, deduplication, metadata tagging) to enable effective indexing.
- Understand indexing and retrieval: how documents are stored (vector or inverted indices) and how similarity search fetches relevant content.
- Learn how generated answers synthesize retrieved content, and how to mitigate hallucinations and verify accuracy.
❓ Frequently Asked Questions
What does RAG stand for?
RAG stands for Retrieval-Augmented Generation, a system that combines a retriever and a generator to answer questions using external knowledge.
What happens during Ingestion in a RAG pipeline?
Ingestion collects and prepares data sources, cleans and normalizes text, and chunks it into manageable pieces for indexing and retrieval.
What is indexing in a RAG system?
Indexing creates a searchable vector store by converting text chunks into embeddings, enabling fast similarity-based retrieval.
What is retrieval in a RAG pipeline?
Retrieval searches the index to fetch the most relevant chunks for a given query, providing context for generation.
What is generation in RAG?
Generation uses a language model to produce the final answer from the retrieved context, synthesizing and presenting information.