Real-Time Ingestion and Streaming RAG Architectures refer to systems that continuously collect and process data as it arrives, integrating it into Retrieval-Augmented Generation (RAG) workflows. These architectures enable AI models to access and utilize the latest information from dynamic sources, ensuring up-to-date, contextually relevant responses. By combining real-time data ingestion with streaming retrieval, they enhance the accuracy and timeliness of generative AI outputs, particularly for rapidly changing information domains.
Real-Time Ingestion and Streaming RAG Architectures
Real-Time Ingestion and Streaming RAG Architectures refer to systems that continuously collect and process data as it arrives, integrating it into Retrieval-Augmented Generation (RAG) workflows. These architectures enable AI models to access and utilize the latest information from dynamic sources, ensuring up-to-date, contextually relevant responses. By combining real-time data ingestion with streaming retrieval, they enhance the accuracy and timeliness of generative AI outputs, particularly for rapidly changing information domains.

💡 Key Takeaways
- Understand real-time ingestion pipelines and how they support streaming RAG.
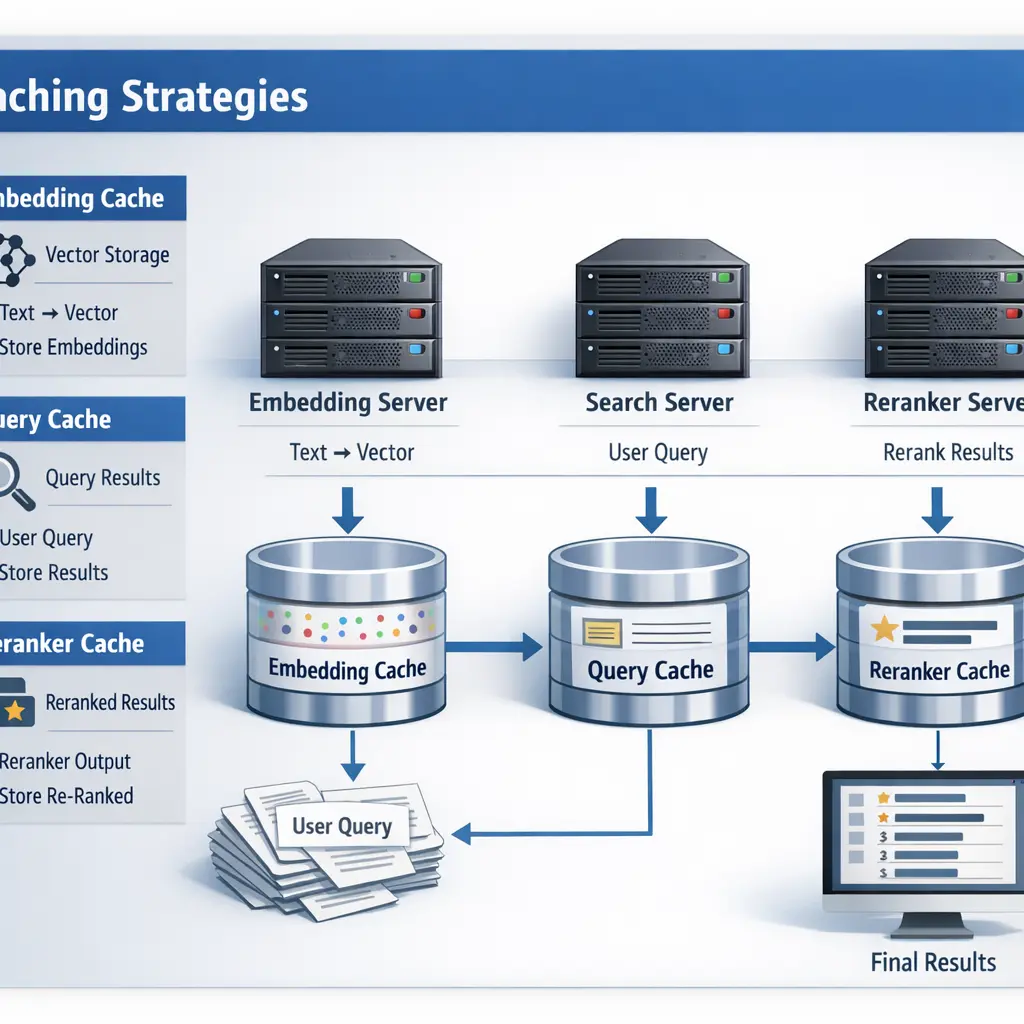
- Learn how streaming platforms (e.g., Kafka, Kinesis) enable low-latency data flows for RAG.
- See how embeddings and vector databases keep retrieved content up to date in streaming RAG.
- Compare real-time and batch ingestion: latency, throughput, and freshness trade-offs.
❓ Frequently Asked Questions
What is real-time data ingestion?
Real-time data ingestion captures and loads data as soon as it is generated, enabling low-latency processing and immediate use in downstream analytics or AI pipelines.
What does RAG stand for and what is its purpose in AI systems?
RAG stands for Retrieval-Augmented Generation. It combines a retriever with a generator to fetch relevant external information and use it to improve the quality and accuracy of generated responses.
What is a streaming RAG architecture?
A streaming RAG architecture integrates real-time data ingestion and streaming processing with retrieval-augmented generation, enabling up-to-date information to be retrieved and used by the generator as data flows in.
What are the common components of a real-time ingestion and streaming RAG pipeline?
Data sources, ingestion/connectors, a streaming platform (e.g., Kafka/Kinesis), stream processing (e.g., Spark/Flink), a vector store for embeddings, a retriever, a generator model, and an interface for users or applications.
How does streaming differ from batch processing in this context?
Streaming processes data continuously with low latency to produce near-real-time results, while batch processing handles data in fixed-sized groups, often introducing higher delays.