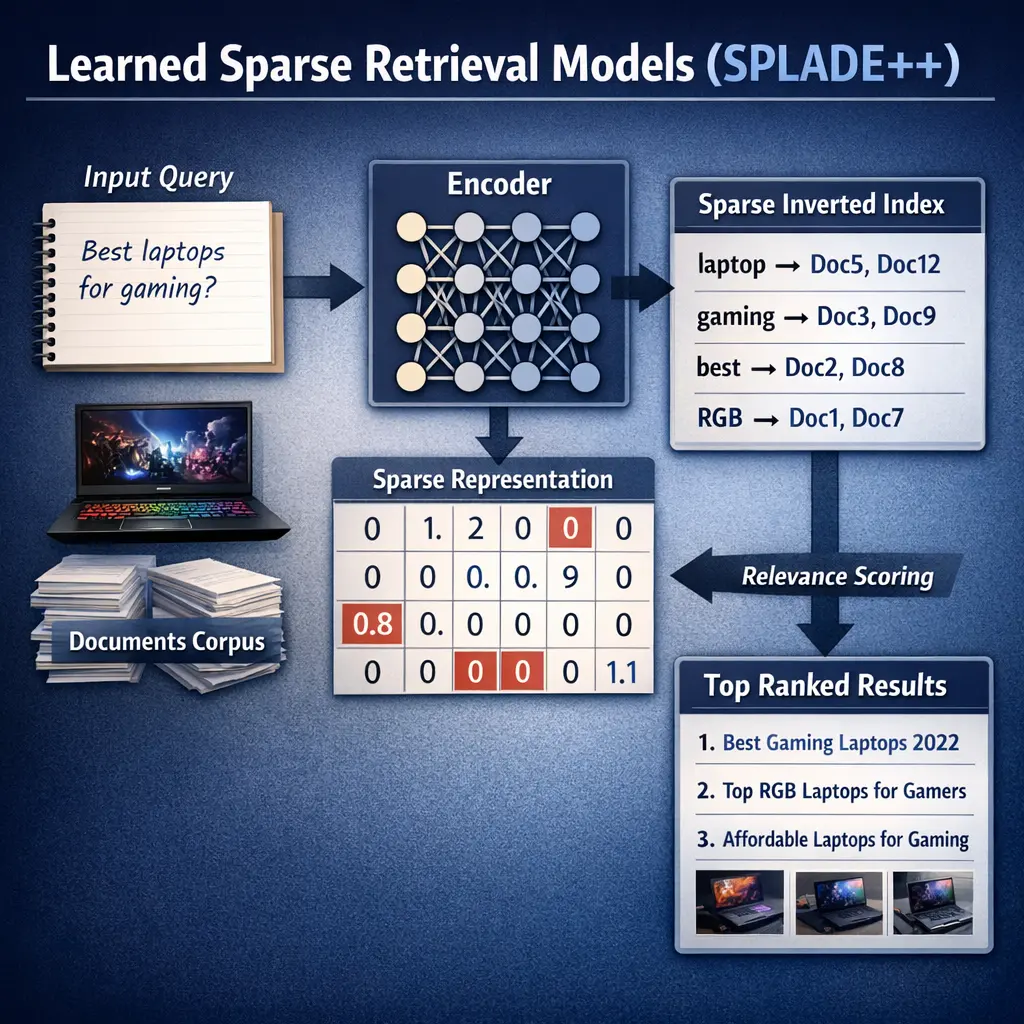
Learned Sparse Retrieval Models (SPLADE++) are advanced retrieval-augmented generation (RAG) techniques that transform input text into sparse, high-dimensional vectors using neural networks. Unlike dense retrieval, SPLADE++ maintains interpretability and efficiency by activating only relevant vocabulary dimensions, enabling effective matching between queries and documents. This approach combines the strengths of traditional sparse methods (like BM25) with deep learning, resulting in improved retrieval accuracy and scalability for large-scale information retrieval tasks.
Learned Sparse Retrieval Models (SPLADE++)
Learned Sparse Retrieval Models (SPLADE++) are advanced retrieval-augmented generation (RAG) techniques that transform input text into sparse, high-dimensional vectors using neural networks. Unlike dense retrieval, SPLADE++ maintains interpretability and efficiency by activating only relevant vocabulary dimensions, enabling effective matching between queries and documents. This approach combines the strengths of traditional sparse methods (like BM25) with deep learning, resulting in improved retrieval accuracy and scalability for large-scale information retrieval tasks.
💡 Key Takeaways
- Understand the core idea: SPLADE++ creates sparse, vocabulary-based representations for queries and documents to enable fast inverted-index retrieval with neural ranking.
- Learn how sparsity is induced: a learned per-term score over a fixed vocabulary with regularization to keep only a subset of terms active.
- See how SPLADE++ fits into IR pipelines: it can work with or alongside traditional methods (e.g., BM25) and leverages standard inverted indexes for efficiency.
- Recognize practical trade-offs: vocabulary size and regularization affect sparsity, indexing cost, and retrieval performance, along with interpretability of term importance.
❓ Frequently Asked Questions
What is SPLADE++?
SPLADE++ is a learned sparse retrieval model that represents text as sparse lexical vectors over a vocabulary, enabling fast inverted-index search while preserving neural ranking benefits.
How does SPLADE++ represent queries and documents?
It maps each query or document to a sparse vector where nonzero weights correspond to terms (or tokens) in the vocabulary, with weights indicating relevance.
How does retrieval work in SPLADE++?
An inverted index stores the sparse document representations. At query time, the query is encoded into a sparse vector and documents are scored by their similarity (e.g., dot product) to the query vector to retrieve top results.
How is SPLADE++ trained and what are its advantages?
It is trained with relevance data using a ranking objective that aligns query–document representations in the sparse space, often with sparsity-inducing regularization. Benefits include efficient inference with an index, interpretability, and strong retrieval quality, with trade-offs like training complexity and vocabulary considerations.