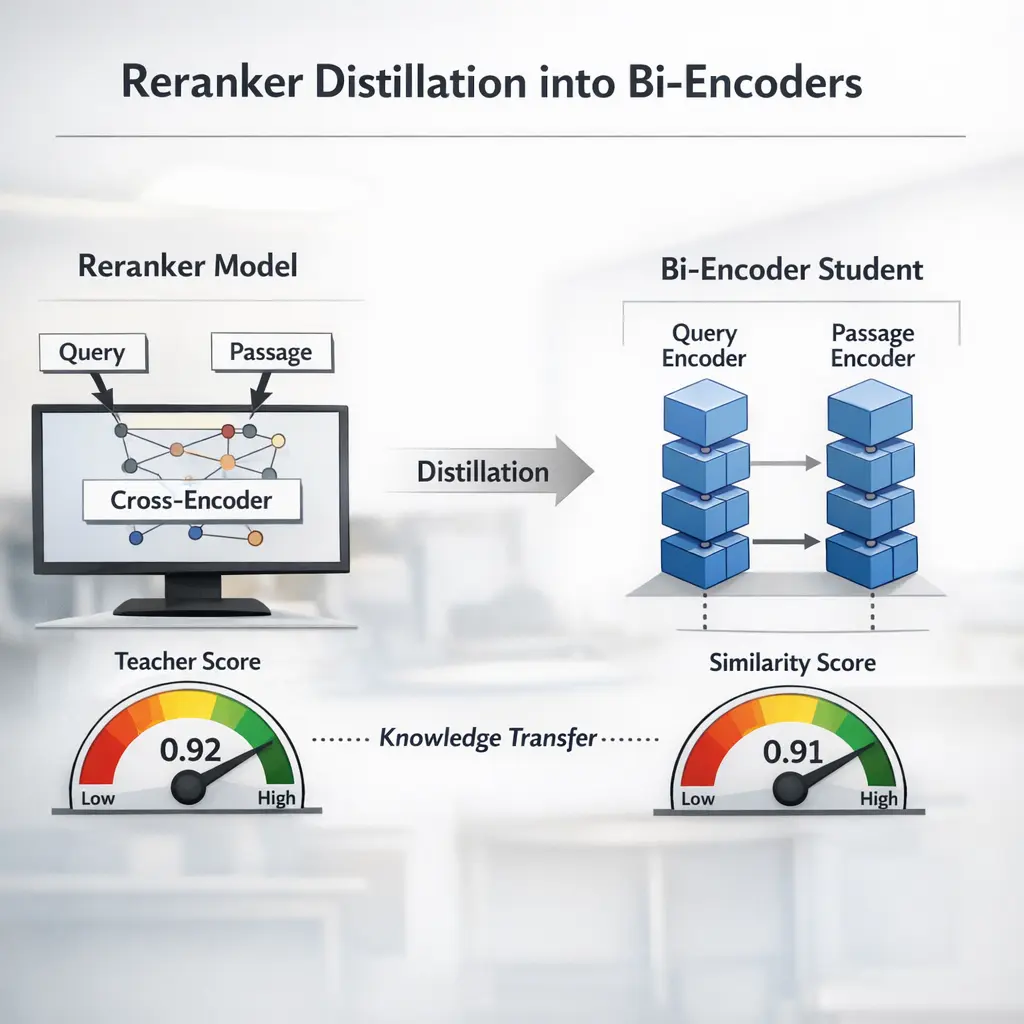
Reranker Distillation into Bi-Encoders is an advanced Retrieval-Augmented Generation (RAG) technique where a powerful reranker model’s knowledge is transferred into a bi-encoder system. Traditionally, bi-encoders are efficient but less accurate than cross-encoders or rerankers. By distilling the reranker’s judgments into the bi-encoder’s training, this method improves retrieval quality while maintaining the speed and scalability of bi-encoders, enhancing overall RAG performance for tasks like question answering or document retrieval.
Reranker Distillation into Bi-Encoders
Reranker Distillation into Bi-Encoders is an advanced Retrieval-Augmented Generation (RAG) technique where a powerful reranker model’s knowledge is transferred into a bi-encoder system. Traditionally, bi-encoders are efficient but less accurate than cross-encoders or rerankers. By distilling the reranker’s judgments into the bi-encoder’s training, this method improves retrieval quality while maintaining the speed and scalability of bi-encoders, enhancing overall RAG performance for tasks like question answering or document retrieval.
💡 Key Takeaways
- Grasp what reranker distillation is and why it helps bi-encoders
- Learn how to distill a reranker into a bi-encoder using teacher-student training
- Compare bi-encoders and rerankers to understand speed vs. accuracy trade-offs
- Identify practical distillation tips and evaluation metrics (MRR, NDCG, negative sampling)
❓ Frequently Asked Questions
What is a reranker in information retrieval?
A reranker is a model that re-scores a short list of candidate documents produced by a fast retriever to improve ranking accuracy, often using deeper or cross-attentive features.
What does distillation mean in machine learning?
Distillation trains a smaller student model to imitate a larger teacher model's outputs, enabling cheaper inference while preserving performance.
What is a bi-encoder, and how does it differ from a cross-encoder?
A bi-encoder encodes query and document separately into vectors and computes similarity; a cross-encoder processes them jointly and usually achieves higher accuracy but is slower.
How does reranker distillation into bi-encoders work?
A teacher reranker scores candidates using a cross-attention model; the student bi-encoder learns to approximate these scores through distillation, enabling fast, approximate ranking.
What are the typical advantages and trade-offs?
Advantages include faster inference and scalable retrieval with near-teacher quality. Trade-offs include some accuracy loss and the need for careful distillation data and training.